
数据类型篇
String
String是最基本的key-value结构,key是唯一标识,value是具体的值。value最大数据长度是512M.
内部实现:
主要用的是int和SDS。
SDS和普通的C语言字符串不太一样,之所以没有使用C语言的字符串表示,是因为SDS的优点:
- SDS不仅可以保存文本数据,还可以保存二进制数据。传统C语言用字符串末尾的/0来判断字符串是否结束,而SDS是用属性值len。
字符串对象的内部编码有三种:int、raw和embstr。
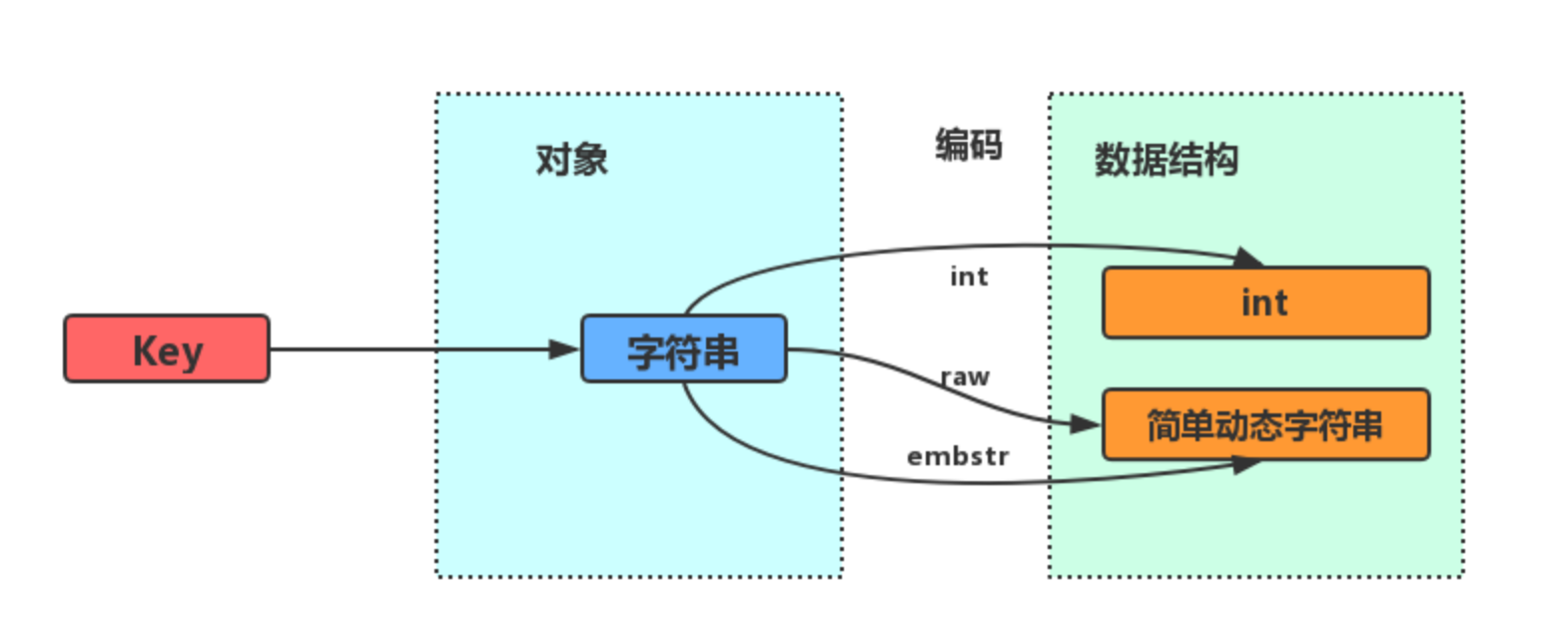
如果一个字符串对象保存的是整数值并可以用long表示,那么字符串对象会把整数值保存在字符串对象结构的ptr属性里面,并且把字符串对象的编码设置成int。
如果字符串对象保存字符串,并且长度<=32字节,那么字符串对象就用的是简单动态字符串SDS来保存,对象编码为embstr,是专门用于保存短字符串的一种优化编码方式。
使用场景:
直接缓存对象,以json的形式。
常规计数,分布式锁,key就是锁名字,value是加锁的客户端,保证只有加锁的客户端才可以释放锁。共享session信息。
List
List泪飙是简单的字符串列表,按照插入顺序排序,可以从头部或者尾部向List列表添加元素。
内部实现
底层数据结构是由双向链表或者压缩列表实现的。最大长度为2^32-1,也就是每个列表支持超过40亿个元素。
如果列表元素小于512个并且每个元素小于64个字节,Redis会使用压缩列表作为List类型的底层数据结构
如果不满足,那么就使用双向链表作为List类型的底层数据结构。
但是在Redis3.2之后,List的底层数据结构就改成了quicklist实现。
应用场景
- 消息队列 消息队列在存取消息的时候,必须满足三个需求,分别是消息保序,处理重复的消息和保证消息可靠性。
- 如何满足消息保序需求?
为什么要满足消息是有序的?假设一种业务场景,创建订单 -> 支付订单 -> 发货 若消息顺序颠倒为发货-> 支付,那么业务上就导致了异常,不应该出现先发货再支付的情况。
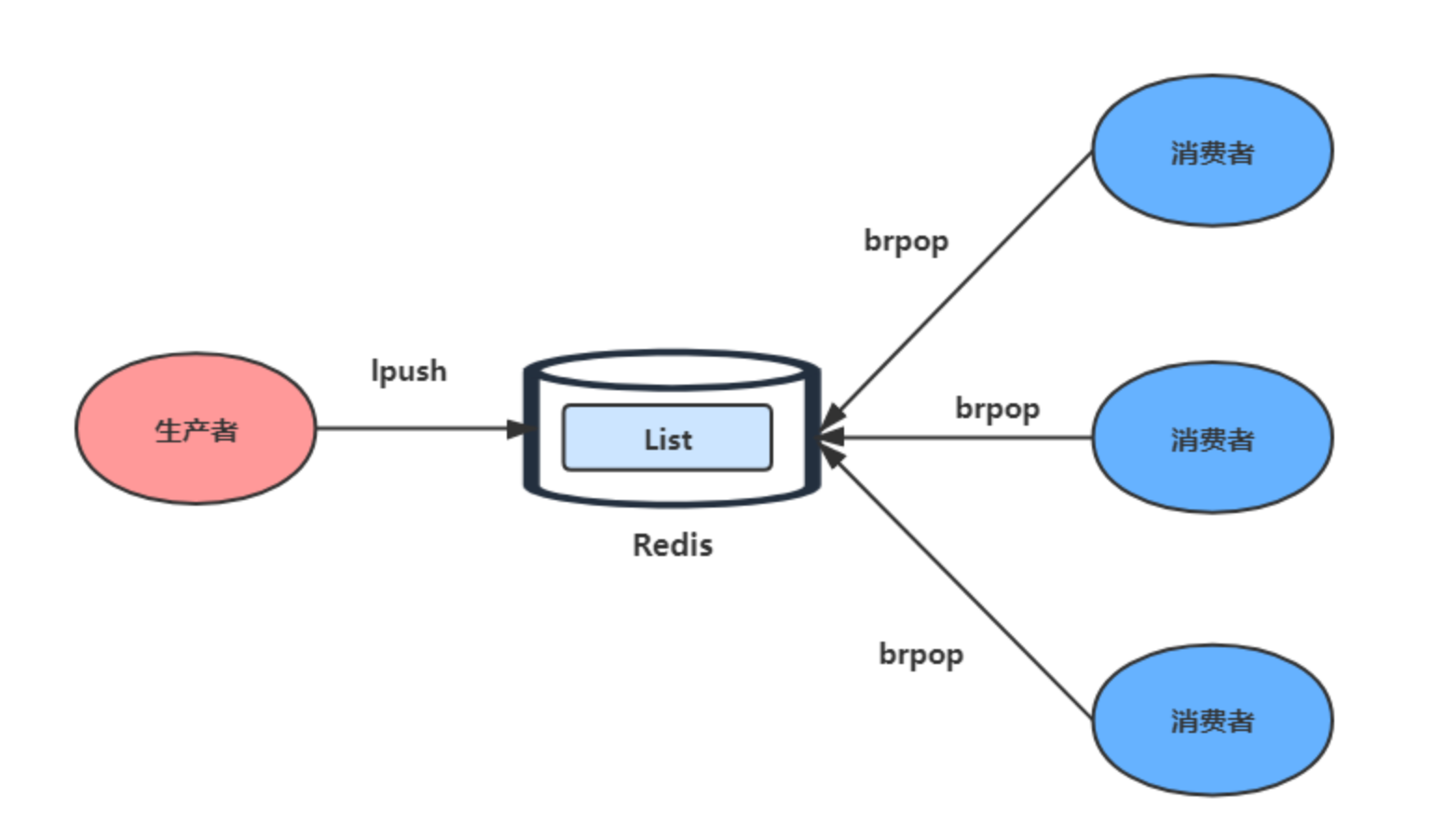
List本身是按照先进先出的顺序对数据进行存储,可以使用LPUSH + RPOP命令实现消息队列。
生产者使用 LPUSH key value 将消息插入到队列的头部,消费者用RPOP key依次读取队列的消息,先进先出。
不过消费者在读取数据的时候有潜在的风险性能点。
生产者往list写入数据,消费者并不会知道有新的消息写入了,需要不断调用RPOP命令。如果有新消息写入,RPOP就会返回结果,否则返回空值。
所以如果长时间没消息写入,消费者就会一直空耗CPU。为了解决这个问题,Redis提供了BRPOP命令,称为阻塞式读取,客户端在没读取到数据的时候自动阻塞,直到有新的数据写入队列再开始读取新的数据。
 2. 如何处理重复的消息?
2. 如何处理重复的消息?
需要保证两步:
- 每个消息都有一个全局的ID
- 消费者要记录已经处理过的消息ID,收到一条消息,消费者程序会对比收到的消息ID和记录的已处理过的消息ID判断当前消息是否已经处理。
但是List不会为每个消息生成ID号,要自行为每个消息生成一个全局唯一ID。
比如:
LPUSH mq "111000102:stock:99"
(integer) 1上面这条命令就把一条全局ID为111000102、库存量为99的消息插入了消息队列。
- 如何保证消息的可靠性?
当消费者读取了一条消息之后,List里面就没有这条消息了。如果处理过程出现了故障,消息就没有处理完成,丢失掉了。
为了留存消息,List类型提供了BRPOPLPUSH 命令。这个命令是让消费者程序从一个List中读取消息,同时,Redis会把这个消息再插入到另一个List,可以叫做备份List留存。
这样,如果消费者程序读取了消息但是没能正常处理,等它重启后,就可以从备份List中重新读取消息并处理。
到这里为止,基于List的消息队列就可以满足消息队列的三大需求:消息有序、处理重复消息和保证消息可靠性。
- 消息保序:用LPUSH + RPOP;
- 重复处理消息:生产者自行生成全局唯一ID。
- 消息可靠性:BRPOPLPUSH
List作为消息队列的缺陷
List不支持多个消费者消费同一条消息。在rocketMQ中,可以有多个消费者组订阅同一个消息,然后每个消费者组独立维护消费进度。
但是从Redis5.0开始,Stream数据类型可以满足消息队列的需求,也支持消费者组的形式进行消息读取。
Hash
内部实现
由压缩列表或者哈希表实现。
- 如果哈希类型元素个数小于512,所有的值小于64字节,由压缩列表作为实现,否则是哈希表。
在Redis7.0中,压缩列表数据结构已经废弃了,交给listpack数据结构实现。
应用场景
存储对象。
但是实际上,用String + json也是存储对象的一种方式。那么实际是用json还是用hash?
一般对象用String + json存储,对象中某些频繁变化的属性可以考虑用Hash存储。
比如说像用户的购物车,以用户的ID为key,商品ID为field,商品数量为value。购物车是变动频繁的,很符合购物车的特征。
Set
介绍
Set类型是一个无序并且唯一键的键值对集合,它的存储顺序不会按照插入的先后顺序进行存储。
一个集合最多存储2^32-1个元素。Set类型除了增删改查,还支持多个集合取交并差集。
如果集合中元素都是整数并且个数小于512,默认用整数集合作为Set底层数据结构。否则使用哈希表。
应用场景
比较适合数据去重和保障数据唯一性。 Set的差集、并集和交集的计算复杂度较高,所以数据量较大的时候会导致Redis实例卡住。
在主从集群中,为了避免主库因为Set做集合运算被阻塞,可以用从库完成聚合统计。
点赞场景也可以。Set类型就保证了一个用户只能点一个赞。这里举例一个场景,key是文章id,value是用户id。
Set支持交集运算,可以用来计算共同关注的好友、公众号等。
抽奖活动
可以把候选用户存到Set里面。然后用命令随机抽取出用户,就是中奖的ID。
允许重复中奖,用SRANDMEMBER命令。 set random member。
如果不允许重复中奖,就用SPOP命令。
Zset
介绍
Zset是有序集合类型,相比于Set多了一个排序属性score。对于Zset,每个存储元素有两个值。一个是有序结合的元素值,另一个是排序值。
内部实现
由压缩列表或者跳表实现:集合元素小于128,每个元素小于64字节,Redis会用压缩列表作为Zset类型的底层数据结构。否则就是跳表。
Redis7以后,压缩列表数据结构已经废弃了,交给了listpack数据结构实现。
添加命令:ZADD key score member。
应用场景
Zset类型(Sorted Set)可以根据元素的权重来排序,我们可以自己决定每个元素的权重值。比如可以根据插入时间来确定,先插入的权重小,后插入的权重大。
比较典型的应用场景就是排行榜。例如学生成绩的排行榜、游戏积分排行榜等。
以点赞排名为例子,巴拉巴啊。
BitMap
介绍
Bitmap,即为位图。是一串连续的二进制数组。可以通过偏移量定位元素。
内部实现
Bitmap本身是用String类型作为底层数据结构实现的一种统计二值状态的数据类型。
常用场景
签到统计。key是用户和年份、月份信息,然后value就是bit,比如
SETBIT uid:sign:100:202206 2 1上面的命令就是给uid为100的用户,在2022年06月,偏移量为2,也就是六月三日的地方置为1.
如果要检查该用户六月三日是否签到,就用get
GETBIT uid:sign:100:202206 2也可以统计用户在六月份的签到次数
BITCOUNT uid:sign:100:202206也可以统计这个月的首次打卡时间:问题等价于返回bitmap中第一个值为bitvalue的offset位置:
BITPOS uid:sign:100:202206 1上面的命令检查bitmap中从头开始第一个为1的bit的偏移量。这里也可以指定上可选的start和end在结尾,指定要检测的范围。
判断用户登录态
也很简单,假如用户的ID是递增的,那么用户登录了,就给对应的位置置为1.
HyperLogLog
这是用于统计基数的数据集合类型。基数统计就是指统计一个集合中不重复的元素个数。但是要注意,HyperLogLog是基于概率的,标准误差率是0.81%。
优点是在输入元素的数量或者体积非常非常大时,计算基数所需要的内存空间总是固定的,并且很小。
在Redis里面,每个HyperLogLog键只需要花费12KB内存,就可以计算接近2^64个不同元素的基数。
应用场景
百万级网页的UV计数
GEO
RedisGEO是Redis3.2版本新加的数据类型,主要存储地理位置信息,并对存储的信息进行操作。
内部实现
GEO直接使用了Sorted Set集合类型。
Stream
介绍
Redis Stream是Redis5.0新增的数据类型,专门为消息队列涉及的数据类型。
在Stream之前,消息队列的实现方式有各自的缺陷:
- 发布订阅模式:不能持久化,无法可靠地保存消息,对于离线重连的客户端不能读取历史消息。
- List实现的消息队列无法实现重复消费,一个消息消费完就会被删除,而且生产者需要自行实现全局唯一ID。
基于以上问题,Redis5.0推出了Steam类型,也就是这个版本最重要的功能,用于完美地支持消息队列。它支持消息持久化、支持全局生成唯一ID、支持ack确认消息的模式、支持消费组模式等,让消息队列更加地稳定和可靠。
常见命令
- XADD:插入消息,保证有序,自动生成全局唯一ID。
- XLEN:查询消息长度
- XREAD:读取消息,按ID读取数据
- XDEL:根据消息ID删除消息
- DEL:删除整个Stream
- XRANGE:读取区间消息
- XREADGROUP:按消费者组形式读取消息
XADD mymq * name xiaolin
"1654254953808-0"上面语句的的意思是,往mymq这个消息队列中插入一条消息,键是key,value是xiaolin。 插入成功后会返回全局唯一的ID:
- 第一部分是数据插入时,以毫秒为计数的时间戳,第二部分表示在当前毫秒的第n条信息。
消费者通过XREAD从消息队列中读取消息时,可以指定一个消息ID,并从这个消息ID的下一条消息开始进行读取。
redis的的消息中间件会丢失消息,如AOF是每秒写盘,但是是异步的,Redis宕机时可能丢失数据,主从复制也是异步的,主从切换时也可能丢失数据。
Redis Stream消息可堆积吗?
Redis的数据存储在内存中,如果消息积压,内存持续增长,如果超过机器 内存上限,会面临被OOM的风险。
Redis的发布/订阅机制为什么不可以作为消息队列?
发布订阅机制存在以下缺点:
- 发布订阅机制没有基于任何数据类型实现,没有数据持久化的的能力,不会被写入AOF和RDB中,当Redis宕机,数据会全部丢失。
- 发布订阅模式是发后即忘的模式,如果有订阅者重连,无法消费之前的历史消息。
- 当消费端有消息积压时,消费端会被却强行断开,这个参数是在配置文件中设置的。
总结
加油!