
___# Java并发编程 来自王二的Java进阶之路
创建线程的三种方式
- 继承Thread类
- 实现Runnable接口
- 实现Callable接口
控制线程的其他方法
- sleep(),join(),setDaemon(),yield()
join(),是Thread的方法,这个线程执行完后才会轮到后续线程得到CPU执行权。
setDaemon()线程标记为守护线程,就是服务其他的线程。
当所有非守护线程结束时,守护线程会被JVM强行关闭。场景是辅助性、可随时中断的任务,比如监控、心跳、临时缓存清理。
yield()是一个静态方法,标识当前线程让出控制权,重新和其他线程一起参与线程调度。但是可能调度器会继续让这个线程运行。
Java线程的6种状态以及切换
// Thread.State 源码
public enum State {
NEW,
RUNNABLE,
BLOCKED,
WAITING,
TIMED_WAITING,
TERMINATED
}- New 尚未启动的线程,也就是还没调用.start()方法。反复调用同一个线程的.start() 是不可行的,第二次调用就会抛出
IllegalThreadStateException - RUNNABLE 标识当前线程正在运行中。它是在Java虚拟机中运行,也有可能在等待CPU分配资源。它事实上包括了操作系统线程的ready和running两个状态。
- BLOCKED 阻塞状态,线程在等待锁的释放。
- WAITING 线程调用了
Object.wait():使当前线程处于等待状态直到另一个线程唤醒它;Thread.join():等待线程执行完毕,底层调用的是 Object 的 wait 方法;LockSupport.park():除非获得调用许可,否则禁用当前线程进行线程调度。LockSupport 我们在后面会细讲。 - TIMED_WAITING 超时等待,到时间会自动唤醒。 调用如下方法会使线程进入超时等待状态:
Thread.sleep(long millis):使当前线程睡眠指定时间; Object.wait(long timeout):线程休眠指定时间,等待期间可以通过notify()/notifyAll()唤醒; Thread.join(long millis):等待当前线程最多执行 millis 毫秒,如果 millis 为 0,则会一直执行; LockSupport.parkNanos(long nanos): 除非获得调用许可,否则禁用当前线程进行线程调度指定时间;LockSupport 我们在后面会细讲; LockSupport.parkUntil(long deadline):同上,也是禁止线程进行调度指定时间;
- TERMINATED 终止状态,线程执行完毕。
线程组和线程优先级
ThreadGroup是一个标准的向下引用的树状结构,这个设计防止上级线程被下级线程引用而无法有效GC回收。
Thread和ThreadGroup有setMaxPriority方法,设置优先级,优先级高的线程有更大的概率得到执行。
但是最高的优先级是按线程所在的线程组的。线程组优先级是5,内部线程即使手动设置为10,实际上也是5的优先级。
进程和线程
进程是应用程序在内存中分配的空间,也就是正在运行的程序。
CPU用时间片轮转的方式运行进程,给每个进程分配时间段,叫时间片。时间片结束了进程还在运行,就暂停,分配给另一个进程,这个过程叫上下文切换。进程在时间片结束之前结束了,CPU会直接进行切换。
但是进程内部实际上也会有子任务,如果没有线程,进程的任务必须一个个执行,这不是我们想要的,于是有了线程。
进程和线程的区别
进程是独立的运行环境,线程是进程中的一个任务,本质区别是是否占有独立内存空间和其他系统资源。
进程有单独内存空间,一个进程出问题不会影响另一个。进程的创建和销毁要保存寄存器和栈信息,还需要资源的分配回收以及页调度,开销较大;线程只需要保存寄存器和栈信息。
进程是操作系统资源分配的基本单位,线程是操作系统进行调度的基本单位。
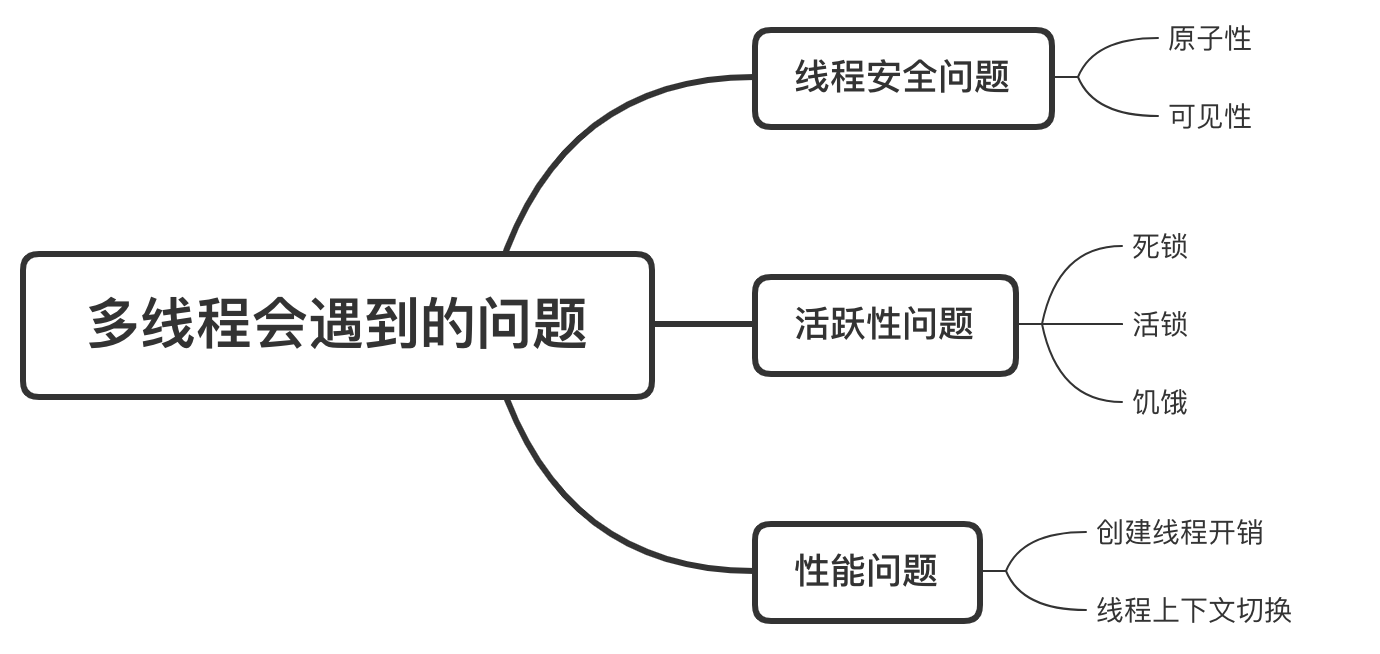
线程安全性问题
int test() {
int i = 0; // 操作1
i++; // 操作2
int j = i; // 操作3
i = i + 1; // 操作4
}上面的操作2和4都不是原子的,包括了读取i的值,+1,写回i三步。
每个线程都有属于自己的工作内存,工作内存和主内存之间要通过store和load等进行交互。
为了解决这个可见性问题,Java有volatile关键字,一个变量被volatile修饰时,保证修改的值会马上更新到主存,确保其他线程可见。
Java的内存模型JMM
Java Memory Model
并发编程存在两个问题:
- 线程间如何通信?
- 线程间如何同步?
两种并发模型可以解决这个问题。
- 消息传递并发模型
- 内存共享并发模型
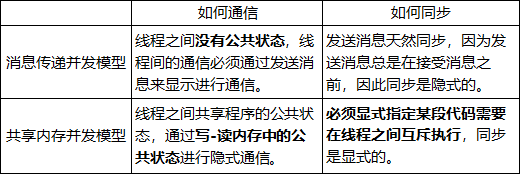
Java使用的是共享内存并发模型
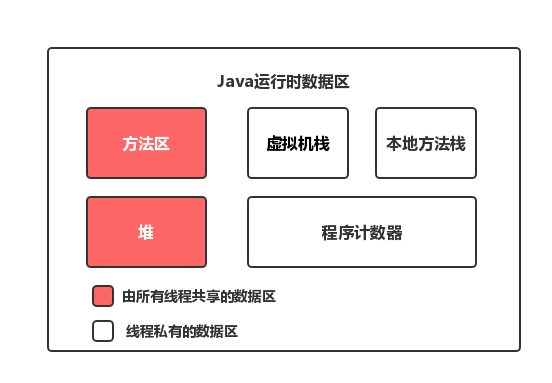
Java运行时数据区:方法区、堆、虚拟机栈、本地方法栈、程序计数器
内存可见性问题是如何发生的?
现代计算机为了高效,会在高速缓存区存储共享变量,因为CPU访问缓存比内存快得多。
所有的共享变量都存在主存中。每个线程保存了一份该线程使用的共享变量的副本。
线程AB之间要通信,必须经过两步:A把本地变量刷新到主存中。B从贮存读取A之前更新的共享变量。
JMM规定,线程对共享变量的所有操作必须在自己的本地内存中进行,不能直接从主存中读取。
为什么要有工作(本地)内存? 这样设计是为了性能考虑。本地内存包含缓存,CPU访问缓存很快。
JMM通过控制主存与每个线程的本地内存之间的交互提供内存可见性保证。
JMM与Java运行时内存区域的区别
两者是不同的概念,JMM是抽象的,是一组规则,围绕原子性、有序性、可见性等展开,Java运行时内存是具体的,是JMM运行Java程序时必要的内存划分
两者都存在私有数据区域和共享数据区域。JMM的主存属于共享数据区域,包含堆和方法区。JMM的本地内存属于私有数据区域,包含程序计数器、本地方法栈、虚拟机栈。
Java运行时内存区域描述在JVM运行时,怎么把内存划分为不同的区域。
- 方法区:存储了每一个类的结构信息,如运行时常量池,字段和方法数据构造方法和普通方法的字节码内容。
- 堆:几乎所有的对象实例和数组都在这里分配内存。这是Java内存管理的主要区域。
- 栈:每个线程有一个私有的栈,每次方法调用会创建新的栈帧,用来存储局部变量、操作数栈等信息。
- 本地方法栈:跟栈差不多,但是是为JVM用到的native方法服务。
- 程序计数器:每个线程独立,指示当前线程执行到了字节码的哪一行。
volatile关键字
它会禁止指令重排。如何实现的?Java内存模型会为volatile变量插入内存屏障(一个处理器指令),实现写屏障和读屏障。
- 写屏障(Write Barrier):当一个volatile变量被写入时,写屏障保证该屏障之前所有变量的写入都提交到主内存。
- 读屏障(Read Barrier):当读取一个volatile变量时,读屏障确保屏障之后的所有读操作都从主存中读取。
synchronized关键字
注意,如果synchronized方法在函数上,实例化两个对象,它们的的对象锁是不一样的。无法保证线程安全。解决方法是把synchronized作用于静态方法,这样锁的就是当前的类,多少个对象都没事。
类上的锁(也就是static的方法)和对象锁(非static方法)不会冲突。
synchronized是可重入锁。在同步块内部再调用有相同锁对象的方法是可以的。
synchronized到底锁的什么?偏向锁、轻量级锁、重量级锁到底是什么?
介绍一下临界区。临界区,指的是某块代码区域,同一时刻只能由一个线程执行。
锁的四种状态以及锁降级
在 JDK 1.6之前,所有的锁都是“重量级”锁,因为是直接用的操作系统的互斥锁,当一个线程持有锁时,其他试图进入同步块的线程都会被阻塞直到锁释放。涉及到了线程上下文切换以及用户态和内核态切换,效率很低。
这也就是为什么很多开发者会认为synchronized性能很差的原因。
为了减少获得锁和释放锁的性能消耗,JDK1.6引入了“偏向锁”和“轻量级锁”。
JDK1.6之后,一个对象实际上有四种锁状态,由低到高分别是:
- 无锁
- 偏向锁
- 轻量级锁
- 重量级锁
锁会随着竞争情况逐渐升级,锁升级很容易发生,但是锁降级发生条件比较苛刻。锁降级发生在Stop The World。
对象的锁放在什么地方?
Java的锁是基于对象的。 首先来看看一个对象的锁是存放在什么地方的?
每个Java对象都有一个对象头。如果是非数组类型,用两个字宽存储对象头,如果是数组,会用三个字宽存储对象头。在32位处理器中,一个字宽是32位;64位同理。
Java中,监视器monitor是一种同步工具,用于保护共享数据,避免多线程并发访问导致数据不一致。在Java中,每个对象都有一个内置的监听器。
监视器包括两个重要部分,一个是锁,一个是等待/通知机制。后者是通过object类的wait(),notify()等方法实现的。
偏向锁
偏向锁会偏向于第一个访问锁的线程。如果接下来运行过程中,该锁没有被其他的线程访问,则持有偏向锁的线程永远不需要触发同步。偏向锁在无竞争下消除了同步语句,连CAS都没有。
偏向锁在第一次进入同步块时,会在对象头和栈帧中的锁记录里面存储偏向锁线程ID。下次线程进入同步块的时候会查看线程ID是不是自己的。
如果是,说明当前线程获得了锁。如果不是,说明有其他线程在竞争锁。这个时候会尝试CAS来替换MarkWord里面的线程ID为新线程ID。
这个时候会尝试用CAS替换Mark Word里面的线程ID为新线程ID:
- 成功替换,说明之前的线程不存在了,Mark Word里面的线程ID是新线程ID,锁不会升级。
- 失败,说明之前的线程依然存在,暂停它,设置偏向锁标识为0,并设置锁标志位为00,升级为轻量级锁,按照轻量级锁的方式进行竞争锁。
撤销偏向锁
偏向锁升级为轻量级锁时,会暂停拥有偏向锁的线程,重置偏向锁标识,这个过程看起来容易,但是开销很大。
- 在安全点(这个时间点上没有字节码执行)停止拥有锁的线程。
- 遍历线程栈,如果存在锁记录,要修复锁记录和Mark Word,使其变成无锁状态。
- 唤醒被停止的线程,将当前锁升级为轻量级锁。
所以如果锁通常处于竞争状态,偏向锁会成为一种累赘。
轻量级锁
JVM会为每个线程在当前线程的栈帧中创建用于存储锁记录的空间,叫Displaced Mark Word。如果一个线程获得锁的时候发现是轻量级锁,会把锁的Mark Word复制到自己的Displaced Mark Word 里。
然后线程尝试CAS把锁的Mark Word替换为指向锁记录的指针,成功当前线程获得锁,失败表示Mark Word已经被替换成了其他线程的锁记录,说明在与其它线程竞争锁。当前线程就尝试使用自旋来获取锁。
自选要消耗CPU,一直获取不到就一直自旋了。
JDK是适应性自旋,如果这次自旋成功,下次自旋次数变多,否则减少。
自旋不是永远的,自旋到一定程度还没获取到锁,自旋失败,线程阻塞,同时锁升级为重量级锁。
轻量级锁的释放
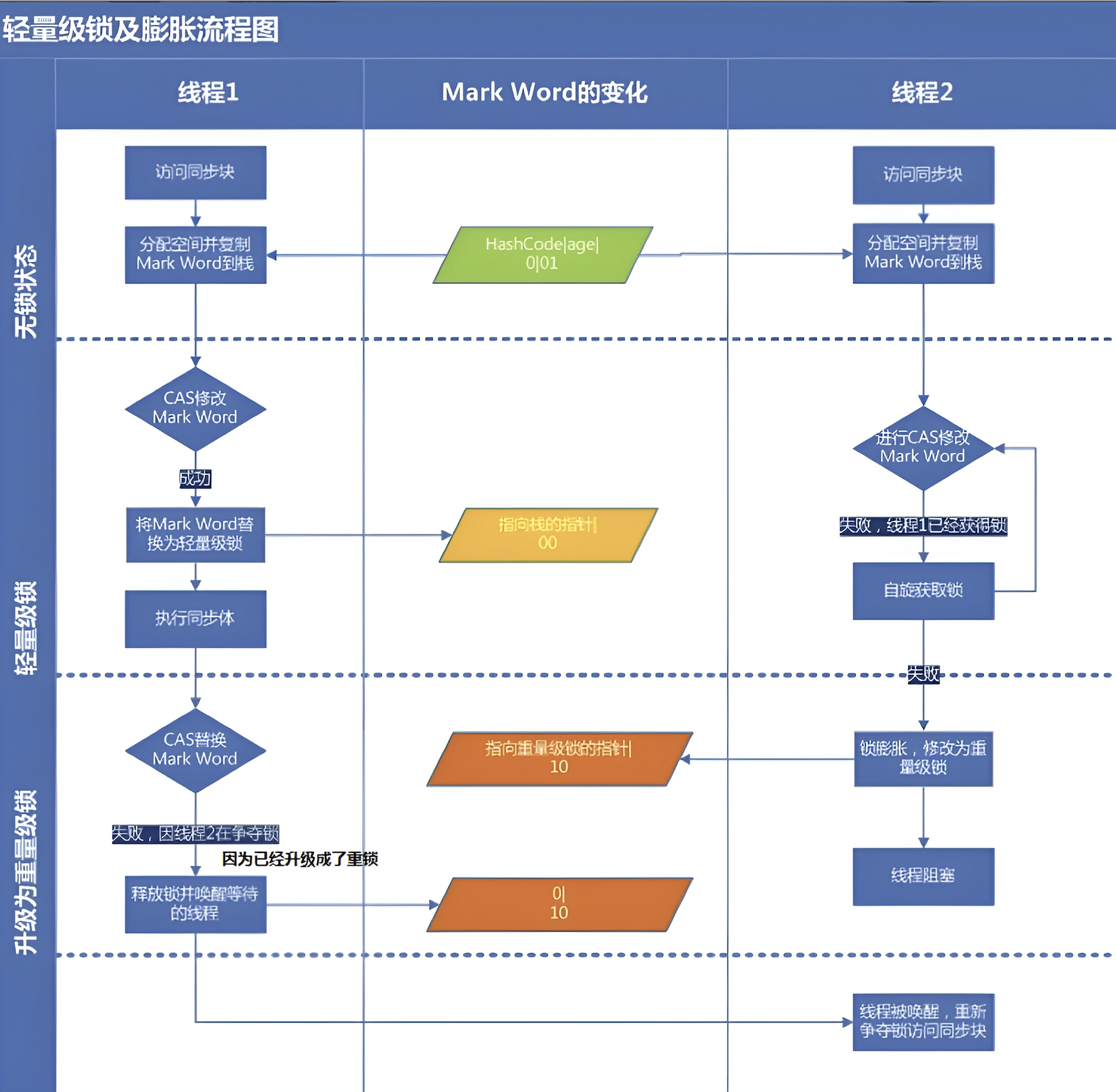
释放锁时,当前线程会用CAS把Displaced Mark Word的内容复制回锁的Mark Word里面。如果没有发生竞争,那么复制操作会成功。
如果没有竞争,那么会复制成功,如果有其他线程因为自旋多次导致轻量级锁升级成了重量级锁,那么CAS操作会失败,此时释放锁并唤醒被阻塞的线程
___
重量级锁
重量级锁依赖于操作系统的互斥锁。线程间状态切换耗时长,所以重量级锁效率低,但是被阻塞的线程不会消耗CPU。
当多个线程同时请求某个对象锁时,对象锁会设置几种状态区分请求的线程。
- Contention List:所有请求所的线程被放在这个竞争队列。
- Entry List:Contention List中有资格称为候选人的线程被移动到Entry List。
- Wait Set:调用wait方法被阻塞的线程被放置到Wait Set
- OnDeck:任何时刻最多只能有一个线程正在竞争锁,该线程称为OnDeck
- Owner:获得锁的线程称为Owner
- !Owner:释放锁的线程
上面的状态藏在每个对象的Monitor对象里,只有重量级锁时才会创建。
当一个线程尝试获得锁时,如果已经被占用,则会把这个线程封装成一个ObjectWaiter对象插入到Contention队首,用park方法挂起。
当线程释放锁时,会从Contention List或EntryList挑选一个线程唤醒,被选中的线程叫Heir presumptive,即为假定继承人,假定继承人被唤醒后会尝试获得锁,但是synchronized是非公平的,所以假定继承人不一定能获得锁。
这是因为对于重量级锁,线程尝试获取锁失败,会直接阻塞,等待操作系统调度。
如果线程获得锁之后调用Object.wait,线程会加入WaitSet中,被Object.notify唤醒后,线程会从WaitSet移动到Contention List或者 EntryList中去。需要注意的是,当调用锁对象的wait和notify方法时,如果当前锁的状态是偏向锁或轻量级锁就会先膨胀成重量级锁。
锁的升级流程
每个线程在准备获取共享资源时,先检查MarkWord里面是不是放的自己的ThreadId。如果是,说明当前处于偏向锁状态。
第二步,如果不是,这时候用CAS来执行切换,新的线程根据MarkWord里面现有的ThreadId,通知之前的线程暂停,之前线程把Mark Word内容置空。
第三步,两个线程都把锁对象的HashCode复制到自己新建的用于存储锁的记录空间,接着用CAS操作,把锁对象的Mark Word内容修改为自己线程内部新建的栈帧地址。
第四步,如果修改成功了,那么CAS成功,该线程获得锁。失败了就进入自旋。
第五步,自旋线程在自选过程中,成功获得资源,仍处于轻量级锁。如果失败。进入重量级锁。自旋进程阻塞,等待之前线程执行完成并唤醒自己.
深入浅出偏向锁
首先是monitor。在编译后,monitorenter指令会被插入到同步代码块的开始位置。monitorexit指令会插入到方法结束和异常的位置。
每个对象都有一个monitor关联,当一个线程执行到monitorenter时,就会获得对象所对应monitor的所有权,也就获得到了对象的锁。
monitor
Java的monitor相当于守门人,确保同一时刻只有一个线程可以访问受保护的代码段。
工作方式
- 进入房间:当线程进入受保护的代码区域时,它必须得到monitor的允许。
- 等待其他线程:如果房间里已有线程,其他线程必须等待。monitor负责让其他线程等候。
- 离开房间:当线程完成它的工作并离开,monitor会重新打开房门,让等待队列中的下一个线程进入。
- 协调线程:monitor还可以通过例如wait和notify、协调线程之间的合作。线程可以通过monitor发信号给其他线程。
Java对象头
Java对象头最多由三部分构成
- Mark Word
- ClassMetadata Address
- Array Length
偏向撤销
偏向锁的撤销和释放是两种机制。释放就是普通的退出同步块。 撤销就是告诉程序这个锁对象不能再使用偏向模式。实践上就是把MarkWord的第三位(是否偏向撤销)值从1变回0.
偏向撤销只发横在有竞争情况下。偏向锁是特定场景下提高效率的方案,但很多地方不满足。容易导致大量的偏向撤销。
大量偏向撤销成本不可以忽视,因此设计有阶梯的底线。
批量重偏向
为每个class维护偏向锁撤销计数器,只要class对象发生偏向撤销,计数器+1,当这个值达到重偏向阈值,默认20时,JVM认为class偏向锁有问题,会进行批量重偏向。
批量撤销
达到重偏向阈值后,达到批量撤销的阈值,默认40时,JVM认为class场景存在多线程竞争,标记class为不可偏向,之后直接走轻量级锁。
偏向锁与HashCode
我们要知道,HashCode不是创建对象就帮我们写到对象头中的,而是要经过第一次调用Object::hashCode() 或者System::identityHashCode(Object)后才会。 偏向锁会来回更改锁对象的Mark Word,对HashCode的生成有影响,怎么办?
实际结论是:即使初始化为可偏向状态的对象,一旦调用了hashCode,进入同步块会直接使用轻量级锁。
另一种场景:已偏向某个线程,后退出同步块,生成了hashcode,然后同一个线程又进入同步块,会发生什么?结论同场景一,直接用轻量级锁。
假如对象已偏向,在同步块中生成hashCode,会直接升级成重量级锁。
wait方法是互斥量独有的,调用wait,会直接升级成重量级锁。
再见了,偏向锁。
JDK 15移除辣!!!
CAS原理
CAS,也就是Compare and Swap,是乐观锁实现方式,无锁的原子操作。
synchronized是悲观锁。
CAS是乐观锁,假设没有冲突,完成某项操作,如果因为冲突失败了,就重试。
悲观锁每次访问资源都加锁,乐观锁就不加。
乐观锁假想操作中没有锁的存在,因此天生免疫死锁.
什么是CAS
V、E、N分别是要更新的变量,预期值,新值。
判断预期值是否等于要更新的变量,是的话,就V=N,不等说明其他线程已经更新。当前线程放弃更新,啥都不做。
CAS的实现是native的。
原子类中的很多方法都是用到CAS。下面是AtomicInteger的getAndAdd方法:
public final int getAndAddInt(Object var1, long var2, int var4) {
int var5;
do {
var5 = this.getIntVolatile(var1, var2);
} while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4));
return var5;
}CAS的三大问题
ABA问题
一个值本来是A、变成了B、又变回A。CAS无法感知,但是实际上是被更新了两次。 从JDK1.5开始,用了AtomicStampedReference类来解决ABA问题,就是加上版本号or时间戳。
它会先检查当前引用是否等于预期引用,并且检查当前标志是否等于预期标志,都相等则设置。
长时间自旋
CAS多与自旋结合,如果CAS长时间不成功,会占用大量CPU。
解决思路是让JVM支持处理器提供的pause指令。pause指令能让自旋失败时CPU睡眠一小段事件再继续自旋,使得读操作频率降低,为解决内存顺序冲突而导致的CPU流水线重排的代价也会小很多。
到底什么是AQS(Abstract Queued Synchronizer)抽象队列同步器?
AQS是一个用来构建锁和同步器的框架。内部用一个双端队列实现。
资源两种共享模式:独占模式和共享模式。
锁分类以及JUC包下的锁介绍,一网打尽。
synchronized的不足之处
- 如果临界区是只读的,其实可以多线程一起执行,但是用synchronized的话,同一时间只能有一个线程执行。
- synchronized无法知道线程有没有成功获取到锁。
- 使用synchronized,如果临界区因为IO或者sleep阻塞,而当前线程没有释放锁,会导致所有线程等待。
临界区(Critical Section)是多线程中一个非常重要的概念,指的是在代码中访问共享资源的那部分,且同一时间只能有一个线程能访问的代码。锁的几种分类
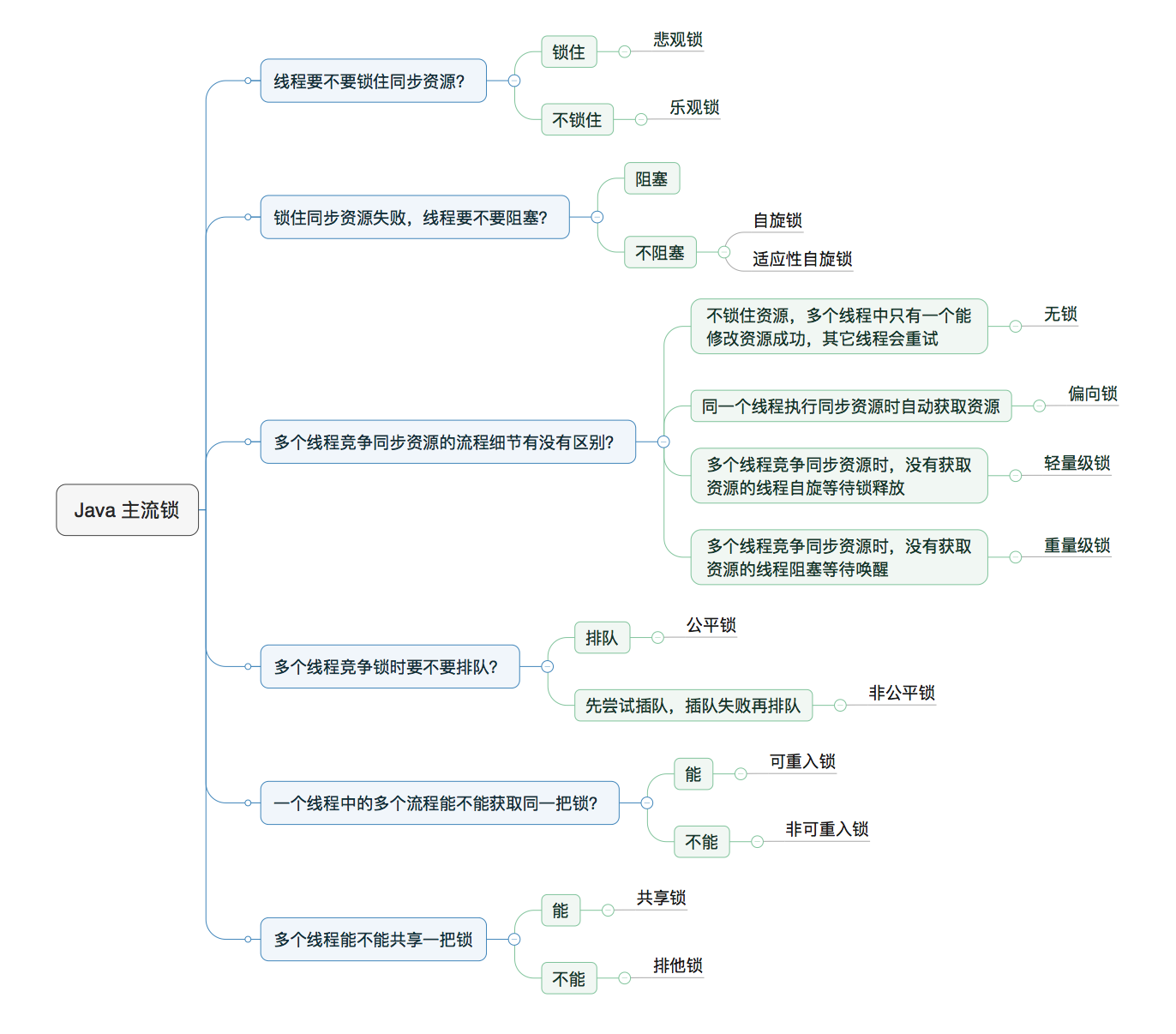
乐观锁和悲伤锁
- 悲观锁适合写操作多,先加锁保证写操作时数据正确
- 乐观锁适合读操作多,不加锁使得性能高
无锁、偏向锁、轻量级锁、重量级锁
前文已经提到
可重入锁和非可重入锁
同上
公平锁和非公平锁
ReentrantLock支持公平锁和非公平锁两种。一般来说非公平锁能提升一定效率,但是非公平锁可能发生线程饥饿。
读写锁和排他锁
读写锁可以在同一时刻允许多个读线程访问。
接口 Condition/Lock/ReadWriteLock
可重入锁ReentrantLock
锁王StampedLock
跳过具体锁的分类
Java的并发容器
吊打Java面试官之ConcurrentHashMap
JDK1.8舍弃了Segment,并且使用了大量的synchronized,以及CAS无锁操作以保证ConcurrentHashMap的线程安全性。
JDK1.7中,ConcurrentHashMap提供了粒度更细的加锁机制,这种机制叫做分段锁。整个哈希表被分为多个段,每个段独立锁定,提高并发性能。
在JDK1.8中,对ConcurrentHashMap做了优化:
- 链表长度为8自动转红黑树。
- 以某个位置的头节点为锁,配合自旋+CAS避免不必要的锁开销
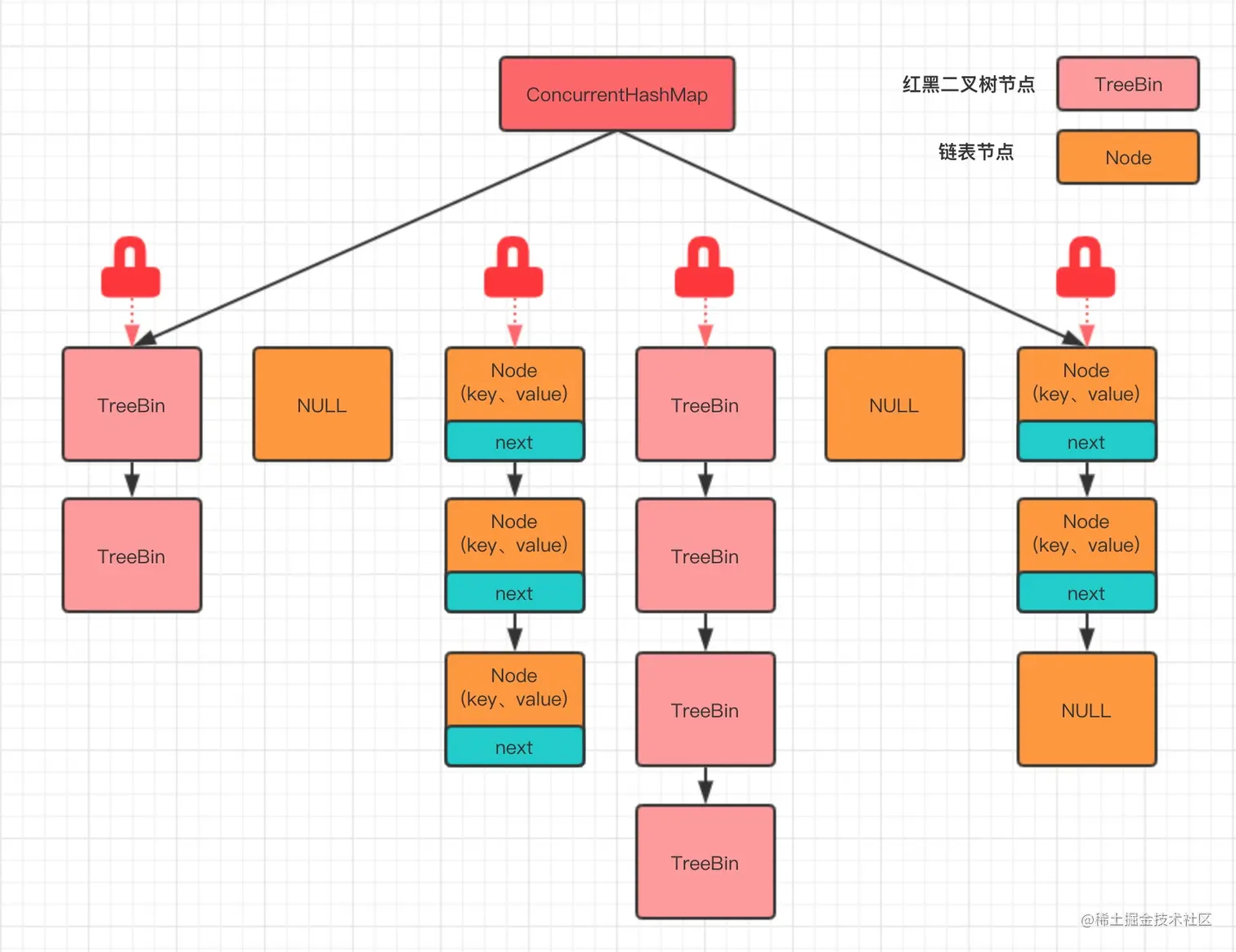
ConcurrentHashMap存储的value是链表,长度大于8转成红黑树。
ConcurrentHashMap的字段:
- table,装在node的数组。作为ConcurrentHashMap的底层容器,采用懒加载的方式,只有第一次插入数据的时候才会初始化,数组大小总是2的幂次方。
- nextTable 扩容时使用,平时为null,只有扩容时为非null。
- sizeCtl 控制table数组的大小,根据是否初始化和是否正在扩容有几种情况:
- 当值为负数,表示正在初始化,如果为-N则标识当前正在有n-1个线程在扩容。
- 值为整数,如果当前数组为null,就表示新建数组长度,否则表示当前table数组的可用容量。跟剩余空间有点区别,具体就是指数的长度n*加载因子loadFactor;当值为零时,数组长度为默认初始值。
- sun.misc.Unsafe U
主要是CAS算法
ConcurrentHashMap的内部类
- Node 主要用于存放键值对,具有next域
- TreeNode 树节点,继承Node类。
- TreeBin 封装了很多TreeNode节点。实际的ConcurrentHashMap数组中,存放的都是TreeBin对象,而不是TreeNode对象。
- ForwardingNode 在扩容时会出现的特殊节点,其 key、value、hash 全部为 null。并拥有 nextTable 引用的新 table 数组。
ConcurrentHashMap的CAS
ConcurrentHashMap会用大量的CAS。
有tabAt方法,获取table数组中索引为i的Node元素。还有casTabAt,setTabAt
initTable 方法
考虑到一种情况,多个线程同时进入初始化方法,为了能够正确初始化,第一步先判断:
if ((sc = sizeCtl) < 0)
// 1. 保证只有一个线程正在进行初始化操作
Thread.yield(); // lost initialization race; just spin如果已经有一个线程在初始化,那么当前线程调用.yield让出时间片。
正在进行初始化的线程会把sizeCtl改成-1.就是正在初始化的状态。
put 方法
ConcurrentHashMap是哈希桶数组,不出现哈希冲突的时候,每个元素均匀分布在哈希桶数组中,出现哈希冲突的时候,用拉链法解决,把hash值相同的节点转换成链表形式,在JDK1.8中,为了防止拉链过长,链表长度大于8的时候,会链表转红黑树。
如果当前节点不为null,且为特殊节点ForwardingNode,说明ConcurrentHashMap当前正在进行扩容。是通过判断节点的hash值是否为-1来判断是不是特殊节点的。
当 table[i] 不为 null 并且不是 forwardingNode 时,以及当前 Node 的 hash 值大于0(fh >= 0)时,说明当前节点为链表的头节点,那么向 ConcurrentHashMap 插入新值就是向这个链表插入新值。通过 synchronized (f) 的方式进行加锁以实现线程安全。
如果在链表中找到了key相同的,就直接覆盖。查到末尾都没查到,就追加到末尾。
get 方法
直接查找,如果在桶的第一个元素中找到了,那么就直接返回。如果第一个节点的hash<0,说明桶的数据结构是红黑树。在这种情况下,使用find方法在红黑树中查找键。 如果都不满足,就遍历链表,找不到的话就返回null。
transfer 方法
用来扩容。
吊打面试官之Java ConcurrentLinkedQueue
深入解析BlockingQueue
阻塞队列最常用于生产者消费者模型。
ArrayBlockingQueue
是阻塞队列的一个实现。
put方法
当队列已经满时,线程移入到notFull等待队列中,满足数据插入条件,就调用enqueue()插入元素。
...
CopyOnWriteArrayList
写时复制是要牺牲一定的数据实时性的。
缺点是有内存占用问题,因为是写时复制,写操作的时候内存里面会有两个对象,旧的对象和新对象的写入。还有数据一致性问题。它只保证数据的最终一致性,不能保证实时一致性。
ThreadLocal
set 方法
public void set(T value) {
//1. 获取当前线程实例对象
Thread t = Thread.currentThread();
//2. 通过当前线程实例获取到ThreadLocalMap对象
ThreadLocalMap map = getMap(t);
if (map != null)
//3. 如果Map不为null,则以当前ThreadLocal实例为key,值为value进行存入
map.set(this, value);
else
//4.map为null,则新建ThreadLocalMap并存入value
createMap(t, value);
}set方法确保每个线程都有自己的变量副本,不同线程互不影响。
ThreadLocalMap是ThreadLocal类的静态内部类。是定制的哈希表,用来保存每个线程中的线程局部变量。
ThreadLocal的HashCode是通过 nextHashCode() 方法获取的,该方法实际上是用 AtomicInteger 加上 0x61c88647 来实现的。
0x61c88647 是一个魔数,用于 ThreadLocal 的哈希码递增。这个值的选择并不是随机的,它是一个质数,具有以下特性:
- 首先是质数,不能被1和它本身之外的数字整除
- 黄金比例:这个数字大约是32位黄金比例浮点数表示的一半,它跟斐波那契数列有关系。
- 递增分布:ThreadLocal中,这个数字用来在哈希表中分散不同线程的哈希码,这个递增的步长有助于哈希表中均匀分配对象。
- 性能优化:这个值使得哈希码均匀分布,减少哈希冲突
线程池
线程池是池化技术的一种实现,核心思想是实现资源的复用,避免资源重复创建和销毁带来的性能开销。线程池可以管理很多线程。
使用线程池的好处:
- 降低资源消耗
- 提高响应速度
- 提高线程的可管理性
线程池的构造
来点核心参数!
- corePoolSize:线程池中用来工作的核心线程数量
- maximumPoolSize:最大线程数,线程池允许创建的最大线程数
- keepAliveTime:超出corePoolSize后创建的线程存活时间或者是所有线程最大存活时间
- unit:keepAliveTime的时间单位
- workQueue:任务队列,是阻塞队列。当线程数达到核心线程数后,会把任务存储阻塞在队列中。
- threadFactory:线程池内部创建线程用的工厂
- handler:拒绝策略。当队列已满并且线程数量达到最大线程数量时,调用这个方法处理任务。
这些参数在线程池中如何工作?
线程池刚创建出来的时候是这样的:
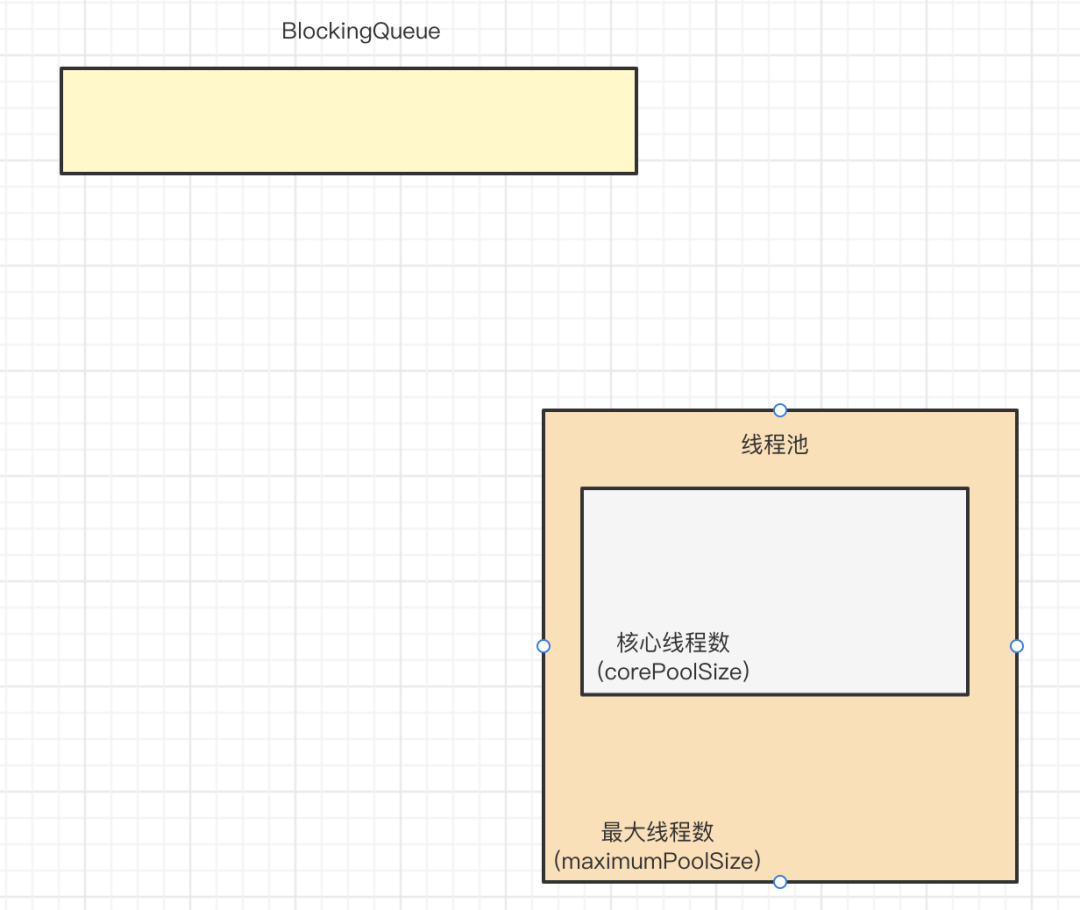
刚创建出来的线程池内是没有线程的。
当有线程通过execute方法提交了一个任务,会发生什么?
首先判断当前线程池的线程数是否小于核心线程数,如果小于,就直接通过ThreadFactory创建一个线程来执行这个任务。
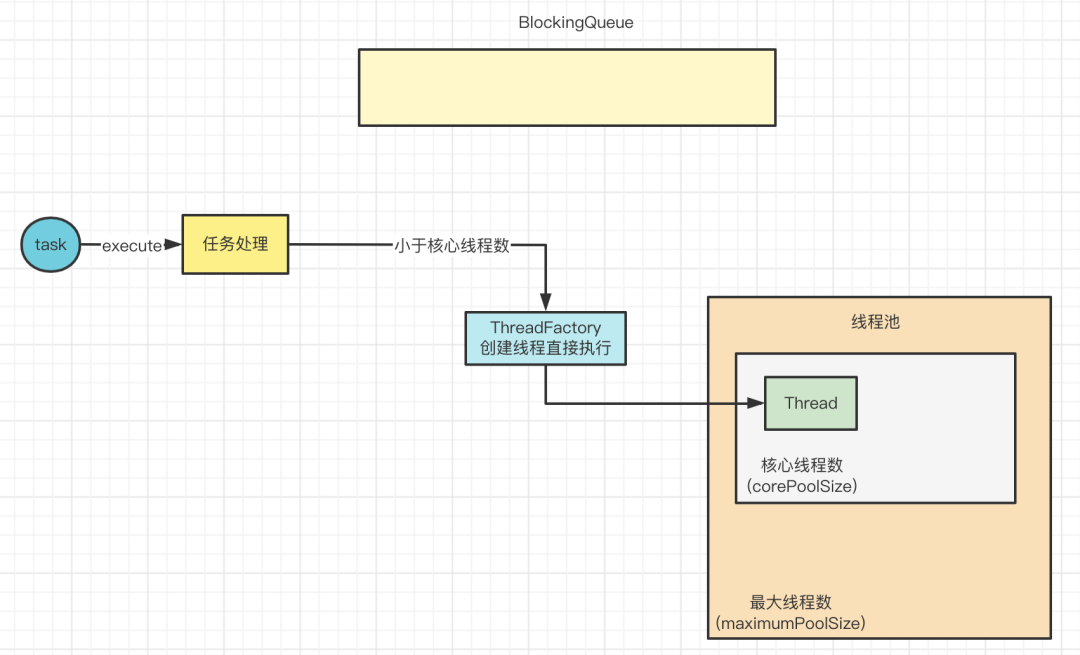
当任务执行完之后,线程不会退出,而是会去阻塞队列中获取任务。
当提交任务的时候,就算有线程池里的线程无法从阻塞队列获取任务,是空闲的,如果线程池里的线程数还是小于核心线程数,线程池依然会选择创建新的线程而不是复用已有的线程。
如果线程池里的线程数不再小于核心线程数,此时提交任务,会放入到阻塞队列中。
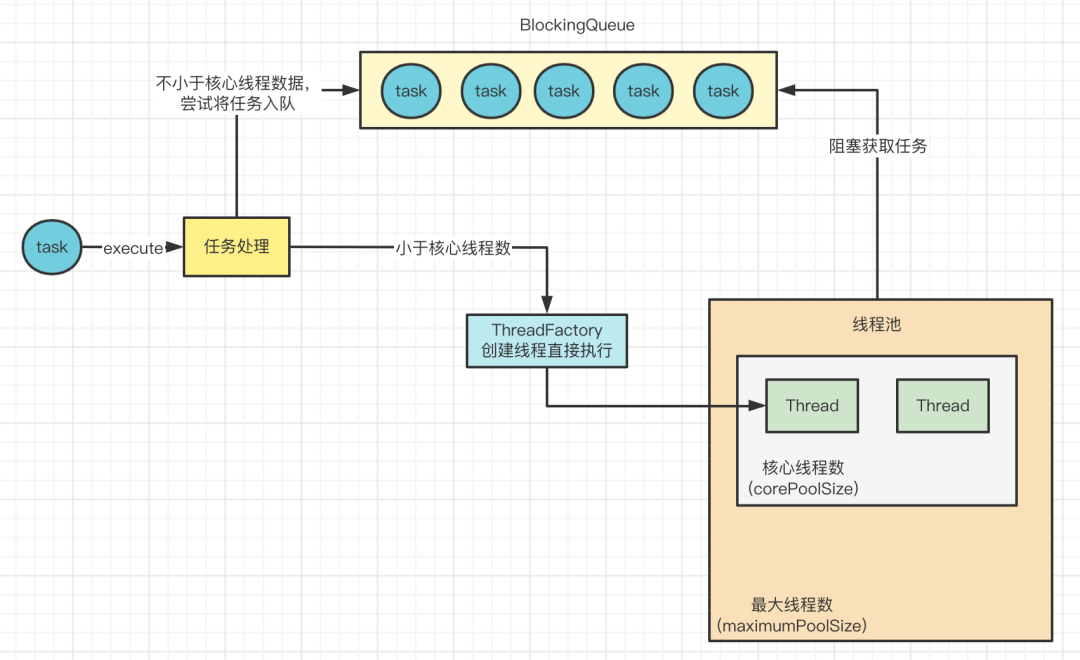
这样,之前空闲下来的核心线程就可以获取到任务了。但是随着任务越来越多,队列已经瞒了,任务放入失败,怎么解决? 此时会判断当前线程池里的线程数是否小于最大线程数,也就是maximumPoolSize 参数。
如果小于最大线程数,那么也就创建非核心线程数来执行提交的任务。
所以,就算队列中有任务,新创建的线程还是会优先处理这个提交的任务,而不是从队列中获取已有的任务执行,这里可以看出,先提交的任务不一定先执行。
假如线程池已经到达了最大线程数,怎么办?
此时就会执行拒绝策略,也就是传入的handler来处理任务。
HDK自带的RejectedExecutionHandler实现有四种
- AbortPolicy:丢弃任务,抛出运行时异常
- CallerRunsPolicy:由提交任务的线程来执行任务
- DiscardPolicy:丢弃任务,但是不抛出异常
- DiscardOldestPolicy:丢弃最早进入队列的任务,然后再次提交这个新的任务
线程池创建的时候,不指定的话,默认是第一个AbortPolicy策略。
线程池线程复用的原理
线程在线程池内部其实被封装成了一个Worker对象。
创建线程执行任务的方法,是通过adderWorker方法,创建Worker对象的时候,会把线程和任务一起封装到Worker内部,然后调用runWorker方法来让线程执行任务。
runWorker源码如下:
final void runWorker(Worker w) {
// 获取当前工作线程
Thread wt = Thread.currentThread();
// 从 Worker 中取出第一个任务
Runnable task = w.firstTask;
w.firstTask = null;
// 解锁 Worker(允许中断)
w.unlock();
boolean completedAbruptly = true;
try {
// 当有任务需要执行或者能够从任务队列中获取到任务时,工作线程就会持续运行
while (task != null || (task = getTask()) != null) {
// 锁定 Worker,确保在执行任务期间不会被其他线程干扰
w.lock();
// 如果线程池正在停止,并确保线程已经中断
// 如果线程没有中断并且线程池已经达到停止状态,中断线程
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt();
try {
// 在执行任务之前,可以插入一些自定义的操作
beforeExecute(wt, task);
Throwable thrown = null;
try {
// 实际执行任务
task.run();
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
// 执行任务后,可以插入一些自定义的操作
afterExecute(task, thrown);
}
} finally {
// 清空任务,并更新完成任务的计数
task = null;
w.completedTasks++;
// 解锁 Worker
w.unlock();
}
}
completedAbruptly = false;
} finally {
// 工作线程退出的后续处理
processWorkerExit(w, completedAbruptly);
}
}从源码里可以找出线程执行完任务不会退出的原因。 runWorker内部使用了while死循环,第一个任务执行完之后,会不断地通过getTask方法获取任务。只要能获取到任务,就会调用run继续执行任务。这就是线程池能够复用的原因。
这里的细节是,Worker继承了AQS,每次执行任务之前都会调用Worker的lock方法,执行后就unlock,这样做的目的是通过Worker的加锁状态判断出当前线程是否正在执行任务。
但是为什么要这样通过锁状态判断线程是否在执行任务?
答案是:为了安全地判断线程是否正在执行任务,并且精准控制中断!用变量虽然简单,但是并发情况下难以保证安全性。
下面内容参考文章:https://www.cnblogs.com/thisiswhy/p/15493027.html
思考:为什么要加锁?说明要占有共享资源。占有什么?
这里面两个都需要写入,一个是workers,一个是largestPoolSize变量。
workers的数据结构是线程不安全的HashSet。 largestPoolSize是int变量,记录线程池中曾出现过的最大线程数。
那么为什么largestPoolSize变量不直接用volatile修饰?而是需要上锁?
其实线程池里面的很多其他字段都用到了volatile,那么为什么这个largestPoolSize不需要?
假设一个场景:如果addWorkers方法还没来得及修改largestPoolSize的值,就有线程调用了getLargestPoolSize方法,由于没有阻塞,直接get到的值不一定是addWorkers方法执行完成后的。
加上锁阻塞,get到的就一定是addWorker方法执行完成后的数字了。
那么为什么存储workers,需要的是非线程安全的HashSet呢?
作者说,事实证明,使用锁还是比较好的。
首先有一个方法叫interruptIdleWorkers,这个方法进去的第一步是拿mainLock锁,然后尝试做中断线程操作。
由于有锁的存在,多个线程调用这个方法,就被serializes串行化了起来。串行化的好处?
避免不必要的中断风暴。
假设我们使用的是并发安全的 Set 集合,不用 mainLock。
这个时候有 5 个线程都来调用 shutdown 方法,由于没有用 mainLock ,所以没有阻塞,那么每一个线程都会运行 interruptIdleWorkers。
所以,就会出现第一个线程发起了中断,导致 worker ,即线程正在中断中。第二个线程又来发起中断了,于是再次对正在中断中的中断发起中断。
因此,这里用锁是为了避免中断风暴(interrupt storms)的风险。
并发的时候,只想要有一个线程能发起中断的操作,所以锁是必须要有的。有了锁这个大前提后,反正 Set 集合也会被锁起来,索性就不需要并发安全的 Set 了。
但是addWorker为什么又调用传入的worker的锁,而不是mainLock?
worker类存在的主要意义是为了维护线程的中断状态。
线程池的五种状态。
- RUNNING:线程池创建时的初始状态,能够接收新任务,以及对已经添加的任务进行处理。
- SHUTDOWN:调用shutdown方法,线程池就会转换成SHUTDOWN状态。
- STOP:调用shutdownNow方法,线程池就会转换成STOP状态,不接收新任务,也不能继续处理已添加的任务到队列中,并且会尝试中断正在处理的任务的线程。
- TIDYING:SHUTDOWN 状态下,任务数为 0, 其他所有任务已终止,线程池会变为 TIDYING 状态;线程池在 SHUTDOWN 状态,任务队列为空且执行中任务为空,线程池会变为 TIDYING 状态;线程池在 STOP 状态,线程池中执行中任务为空时,线程池会变为 TIDYING 状态。
- TERMINATED:线程池彻底终止。
虽然JDK提供了快速创建线程池的方法,但是其实不推荐用Executors来创建线程池,因为从上面构造线程池的代码可以看出,newFixedThreadPool线程由于使用了LinkedBlockingQueue,队列容量默认无限大,很容易导致内存溢出。
实际项目中怎么合理自定义线程池
- 线程数 线程数的设置主要取决于业务是IO密集型还是CPU密集型
CPU密集型一般没有很多线程阻塞,线程数一般设置为CPU核心数+1
IO密集型一般线程数是2*CPU核心数
- 线程工厂
一般建议自定义线程工厂,比如指定线程名称,查日志的时候方便是哪个线程执行的代码
- 有界队列 一般需要设置有界队列的大小
从根本上理解生产者-消费者模式
实现生产者-消费者模式时,可以采用三种方式:
- 用Object的wait/notify的消息通知机制
- 使用Lock Condition的await/signal消息通知机制
- 使用BlockingQueue实现。
wait/notify消息通知机制会存在问题:
notify通知过早
notify通知的问题在于,可能存在这样一种情况,即线程A可能还没wait,而线程B就notify了。此时线程B的通知是无效的,而之后A线程再wait,就会一直被阻塞了。