面试篇(Java Guide为主)
创建一个对象用什么运算符?对象实体与对象引用有何不同?
创建对象用new,对象引用指向对象实例。
- 一个对象引用可以指向0 or 1个对象。
- 一个对象可以有N个引用指向它。
对象相等指的是内存中存放的内容是否相等,引用相等一般比较内存地址是否相等
面向对象的三大特点:封装、继承、多态。 封装很好理解,就是把属性隐藏在对象内部,不让外部访问,但是暴露一些set方法之类的间接提供给外部进行访问。
继承页很好理解,就是子类继承父类。
多态是什么意思?
多态就是一个对象有多种状态,具体表现为父类的引用指向子类的实例。
接口和抽象类的共同点和区别?
接口和抽象类的共同点
- 实例化:接口和抽象类都不能直接实例化,只能被实现或者继承后才能创建具体对象。
- 抽象方法:接口和抽象类都可以包含抽象方法。
区别:
- 设计目的:接口用于对类的行为进行约束,实现某个类就有对应行为。抽象类用于代码复用,强调所属关系。
- 继承和实现:一个类只能继承一个类,但是可以实现多个接口。
深拷贝和浅拷贝的区别
- 浅拷贝:也会在堆上创建一个新的对象,对于被复制的对象,如果属性是引用类型,则只会复制这个引用类型的地址,实际上和原对象指向的依然是同一个对象。
- 深拷贝:完全递归复制整个对象,包括对象内部的引用对象也是新的。
Object类的常见方法有哪些?
hashCode(),equals(),clone(),toString(),notify(),notifyAll(),wait(),finalize().
==和equals的区别
==对基本类型和引用类型的效果不一样。对于基本类型,判断的是值是否相等,对引用类型,比较的是地址是否相等。
equals不能判断基本数据类型的变量,只能判断两个对象是否相等。
如果类没有重写equals方法,那么其实等价于用==比较。
String、StringBuffer、StringBuilder区别?
String中的对象是不可变的,线程安全。StringBuffer对内部的方法加了同步锁,是线程安全的,而StringBuilder没有,速度更快,但非线程安全。
每次对String类型进行改变的时候,都会生成一个新的String对象,然后指针指向新的String对象。
String为什么是不可变的?
使用final关键字修饰字符数组来保存字符串,所以String对象是不可变的。但是我们知道final修饰后,数组的内容其实还是可以修改的,String不可变根本原因是内部chars数组是私有的,并且没有暴露修改方法给外部。
在Java9之后,String实现改用bytes数组,再加上编码指示,使得支持Latin-1和UTF-16两种编码方式。前者用byte表示占一个字节,用char表示占2个字节。会节省空间。前提是字符串只包含能用Latin-1表示的字符。
字符串拼接用+还是StringBuilder?
Java语言本身是不支持运算符重载的,+和+=是专门为String类重载的运算符。
字符串通过+拼接,在字节码内是StringBuilder调用append()。但是有个问题,在循环内使用+拼接的话,编辑器它不会复用StringBuilder,而是每次循环新建。
字符串常量池了解吗?
字符串常量池在堆中,主要是为了避免字符串的重复创建。
// 在字符串常量池中创建字符串对象 ”ab“
// 将字符串对象 ”ab“ 的引用赋值给 aa
String aa = "ab";
// 直接返回字符串常量池中字符串对象 ”ab“,赋值给引用 bb
String bb = "ab";
System.out.println(aa==bb); // trueString s1 = new String("abc");这句话创建了几个字符串对象?
答案是创建1或2个对象。
- 字符串常量池不存在"abc":那么先在字符串常量池中创建它。之后因为有new String(),则在堆中再创建一个,并使用常量池中的abc进行初始化。
- 如果已经存在,那么就跳过上面的第一步,在堆中创建String对象,用常量池中的abc进行初始化
String.intern()方法有什么用?
它是一个native本地方法,比如String.intern("abc"),如果字符串常量池中已经有abc,那么方法返回的就是这个常量池中的对象。如果没有,那么就在常量池中创建abc,并且返回它的引用。
介绍下Java的内存模型?
注意!千万不要和Java的运行时内存区域搞混淆!运行时内存区包括堆、方法区、虚拟机栈、本地方法栈和程序计数器,而内存模型是完全不同的概念。
JMM内存模型定义了Java程序中的变量、线程如何和主存以及工作内存进行交互的规则、涉及到线程之间变量的可见性、指令重排等问题,是理解并发编程的关键!
JMM使用的是共享内存模型。它会有内存可见性问题。
内存可见性问题
堆是所有线程共享的,为什么还有内存可见性问题?因为计算机会用缓存,每个线程都有自己独立的工作内存,而不一定马上修改共用内存部分的变量。
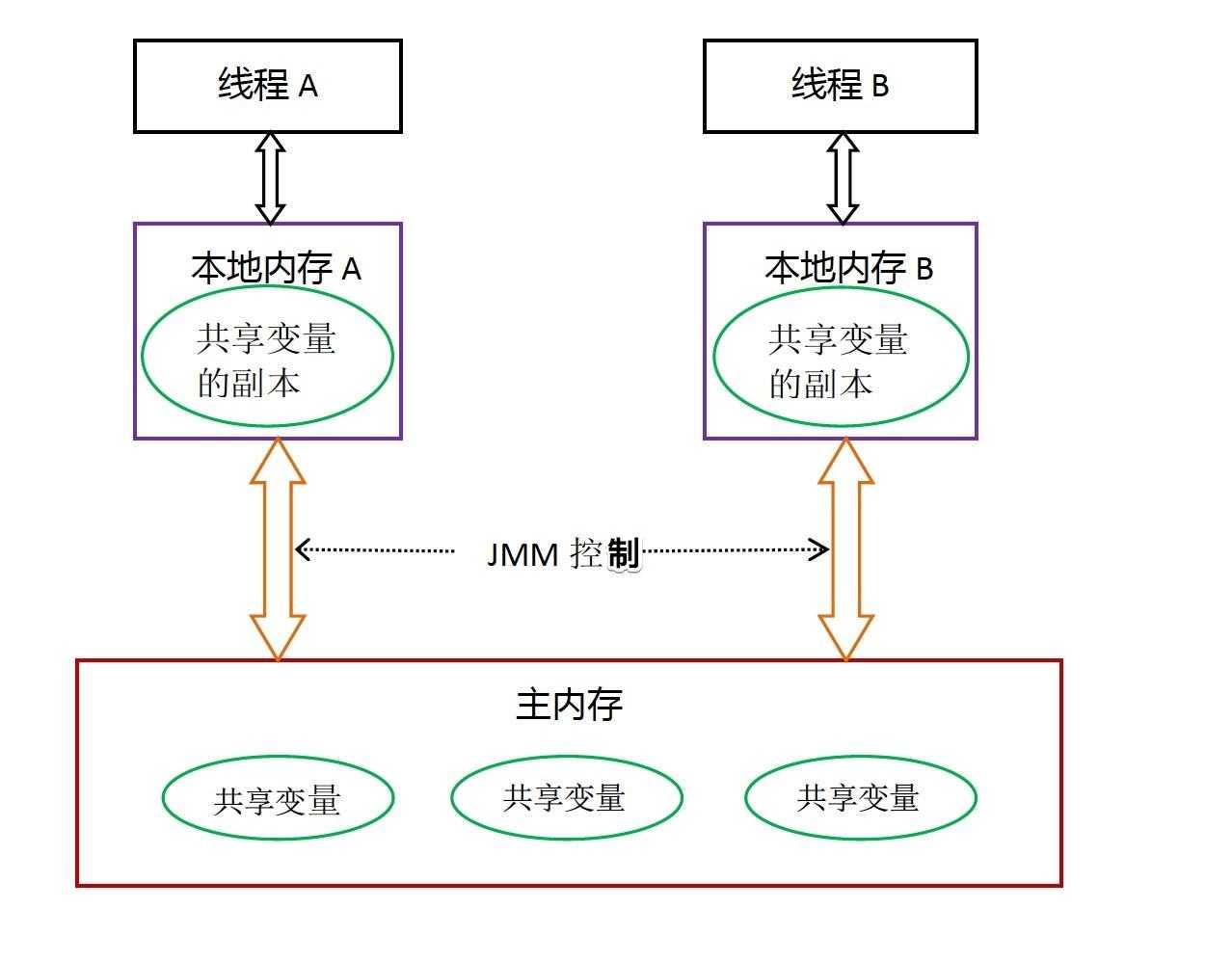
线程A、B通信要两步:A把本地内存中更新后的值同步到主存,B从主存读取A刷新后的值。
所以可以发现,线程AB无法直接访问互相的工作内存,线程间的通信必须经过主存。工作内存优先存储在寄存器和高速缓存,更快。
如何保证内存可见性?
怎么知道这个共享变量被其他线程更新了?这就是JMM的功劳!JMM通过控制主存与每个线程的本地内存之间的交互,提供内存可见性的保证。
Java中的volatile关键字可以保证内存可见性,它有如下两个作用:保证多线程操作共享变量的可见性,以及禁止指令重排。
更底层,HMM通过内存屏障实现内存可见性和禁止重排序。设计者提出了happens-before原则。
JMM和Java运行时内存区域的区别
区别:
两者是不同的概念,JMM是抽象的一组规则,围绕原子性、有序性、可见性等展开,而Java运行时内存的划分是具体的。
联系:
都存在私有数据区域和共享数据区域。
运行时内存区域的部分:
- 方法区:放着每个类的结构信息,运行时常量池、字段和方法数据、构造方法和普通方法的字节码内容。
- 堆:几乎所有对象实例以及数组都在这里分配内存,是Java内存管理的主要区域。
- 虚拟机栈栈:这个简单,每个线程私有,每次调用方法就创建栈帧,存储局部变量、操作数栈和方法返回地址、动态链接。所有栈帧都是方法调用创建、执行完毕销毁。
- 本地方法栈:跟上面一样,为什么单独区分出来?我认为是沙箱机制,毕竟是本地实现,Java不可控。
- 程序计数器:线程独立,指示当前线程执行到了字节码的哪行。
Java内存模型主要针对的是多线程环境下,如何在主内存和工作内存之间安全地工作。
它涵盖的主题包括变量可见性、指令重排、原子操作等,是为了解决多线程并发编程带来的问题。
小结
- JMM定义了Java程序的变量、线程如何在主存和工作内存之间进行交互的规则。它主要涉及到多线程环境下共享变量的可见性、指令重排等问题,是理解并发编程的关键概念。
Java异常
异常结构图:
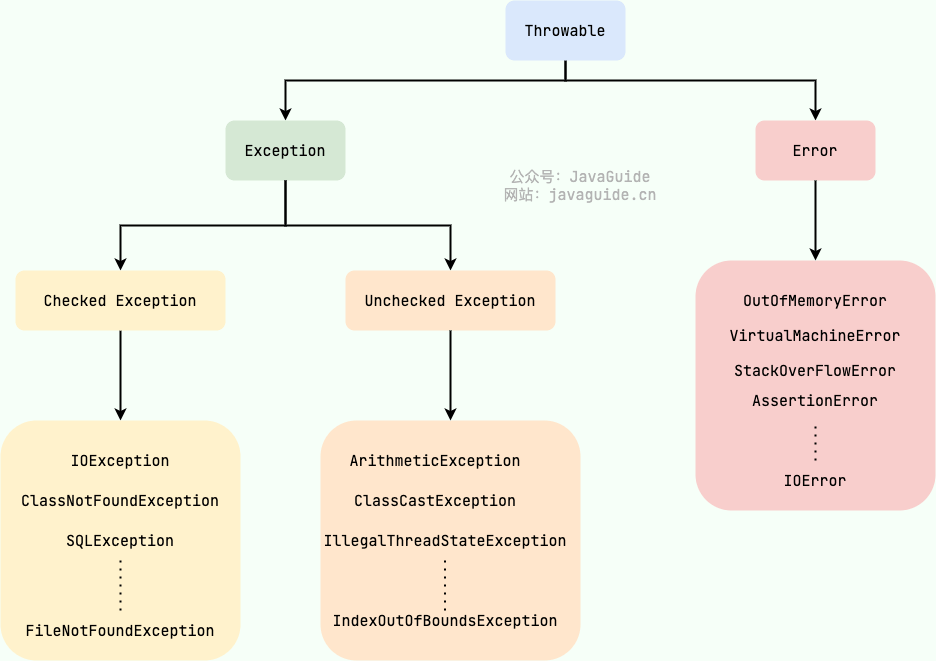
Exception 和Error有什么区别?
在Java中,所有的异常都有一个共同祖先Throwable类。Throwable类有两个重要子类:Error和Exception。
Exception:程序本身可以处理的异常,可以用catch进行捕获。
Error:程序无法处理的错误,不建议用catch捕获。例如OOM、NoClassDefFoundError等。
Checked Exception 和 Unchecked Exception 有什么区别?
Checked Exception,即受检查异常。Java代码在编译过程中如果CE没有被捕获,编译会错误。
除了RuntimeException及其子类以外,其他的Exception类及子类都属于受检查异常。
Unchecked Exception 即 不受检查异常 ,Java 代码在编译过程中 ,我们即使不处理不受检查异常也可以正常通过编译。
RuntimeException和子类都是不受检查异常。
- NullPointerException:空指针错误
- IllegalArgumentException:参数错误
- ArrayIndexOutOfBoundsException:数组越界错误
- ClassCastException:类型转换错误
Throwable的常用方法有哪些?
- String getMessage():返回异常发生时的详细信息
- String toString():返回异常发生时的简要描述
- printStackTrace():在控制台上打印Throwable对象封装的异常信息
try-catch-finally
注意,不应该在finally中使用return。当try和finally中都使用return时,try的return会被忽略。这是因为 try 语句中的 return 返回值会先被暂存在一个本地变量中,当执行到 finally 语句中的 return 之后,这个本地变量的值就变为了 finally 语句中的 return 返回值。
finally也不一定执行,加入虚拟机被终止运行就不行。或者程序所在的线程死亡、CPU被关闭。
反射
反射是Java框架的灵魂!它赋予了我们在运行时分析类以及执行类中方法的能力。通过反射可以获取任意一个类的所有属性和方法。
反射优缺点
反射会让代码更加灵活,为各种框架提供开箱即用的功能提供了便利。
不过反射会有安全问题,比如无视泛型参数的类型检查。不过,对于框架来说实际影响是不大的。
反射的应用场景?
像spring boot、MyBatis什么的都大量使用了反射机制。
另外,像Java中的注解的实现也用到了反射。
注解
注解是Java5开始引入的特性,本质是一个继承了Annotation类的特殊接口。
Java IO
Java IO流有很多类,最基本的是下列的四个抽象类基类和派生类。
- InputStream/Reader:所有的输入流的基类,前者是字节输入流,后者是字符输入流。
- OutputStream/Writer:所有输出流的基类,前者是字节输出流,后者是字符输出流。
IO 流为什么要分成字符流和字节流?
JavaGuide作者认为:
- 字符流是由Java虚拟机将字节转换得到的,可能比较耗时
- 如果不知道编码类型,用字节流容易出现乱码
Java IO模型详解
从计算机结构的视角来看,IO描述了计算机系统与外部设备之间通信的过程。
从应用程序的角度,在操作系统中,用户进程是不能调用IO的,必须委托内核来调用。
从应用程序的视角来看的话,我们的应用程序对操作系统的内核发起 IO 调用(系统调用),操作系统负责的内核执行具体的 IO 操作。也就是说,我们的应用程序实际上只是发起了 IO 操作的调用而已,具体 IO 的执行是由操作系统的内核来完成的。
有哪些常见的IO模型?
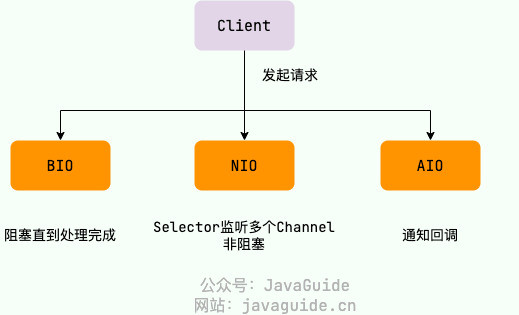
unix系统下,IO模型一共五种:同步阻塞IO、同步非阻塞IO、IO多路复用、信号驱动IO和异步IO。
Java中3种常见的IO模型
BIO
BIO是block io,也就是同步阻塞模型。
同步阻塞 IO 模型中,应用程序发起 read 调用后,会一直阻塞,直到内核把数据拷贝到用户空间。
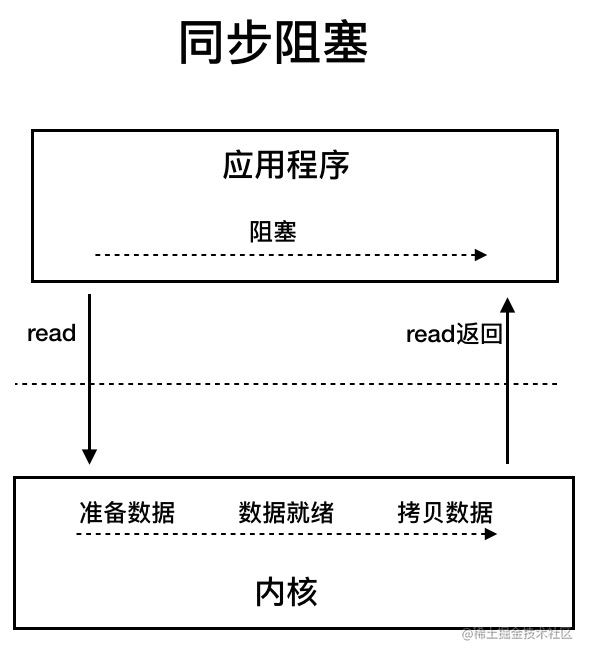
当高并发的时候,传统的BIO模型无能为力,因此我们需要更高效的IO处理模型来应对更高的并发量。
NIO
NIO,Not Blocking IO,是支持面向缓冲的,基于通道的I/O操作方法。对于高负载、高并发的应用,应该使用NIO。
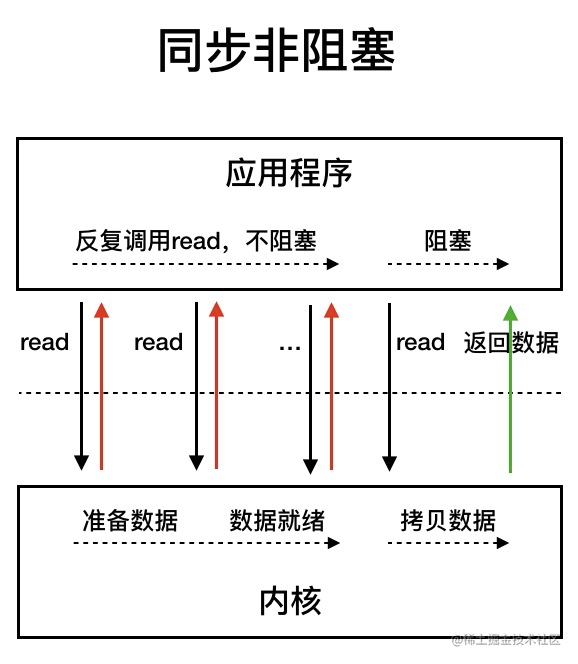
在同步非阻塞模型中,应用程序会一直发起read调用,等待数据从内核空间拷贝到用户空间的这段时间里,线程依然是阻塞的,直到在内核把数据拷贝到用户空间。
相比于同步IO阻塞、同步非阻塞模型通过轮询操作避免了一直阻塞。但是问题是,应用程序不断进行IO系统调用轮询,查询数据是否准备好的过程是非常耗费CPU资源的。
这时候,IO多路复用模型派上了用场。

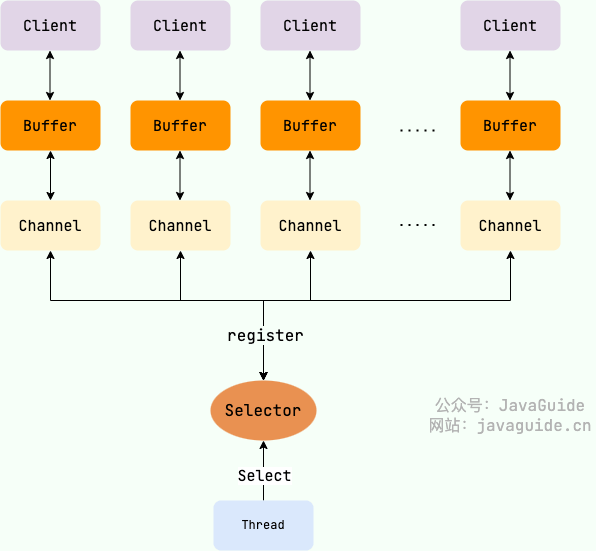
Java 中的 NIO ,有一个非常重要的选择器 ( Selector ) 的概念,也可以被称为 多路复用器。通过它,只需要一个线程便可以管理多个客户端连接。当客户端数据到了之后,才会为其服务。
AIO
asynchronous IO,它是异步IO模型。
异步 IO 是基于事件和回调机制实现的,也就是应用操作之后会直接返回,不会堵塞在那里,当后台处理完成,操作系统会通知相应的线程进行后续的操作。
总结