
常见集合篇
HashMap
hash方法的原理
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}这里为什么不直接用hashCode,而是要做(h = key.hashCode()) ^ (h >>> 16)这样的一个运算?
这个主要是为了让哈希值更加均匀地分布。h右移16位,高位就全为0了。然后再跟原来的哈希值相异或,能让结果更加均匀。
综上,hash方法是用来做哈希值优化的,把哈希值右移 16 位,也就正好是自己长度的一半,之后与原哈希值做异或运算,这样就混合了原哈希值中的高位和低位,增大了随机性。
hashmap的扩容机制
HashMap的扩容是通过resize方法实现的。里面新建一个新的数组newTable,然后把旧的数组oldTable中的元素转移到新数组newTable中。
转移是调用transfer方法实现。方法遍历数组中的每个桶,把每个桶键值对重新计算哈希值,插入到新数组对应的桶中。
在JDK7中,元素从旧的数组转移到新的数组时使用的是头插法。
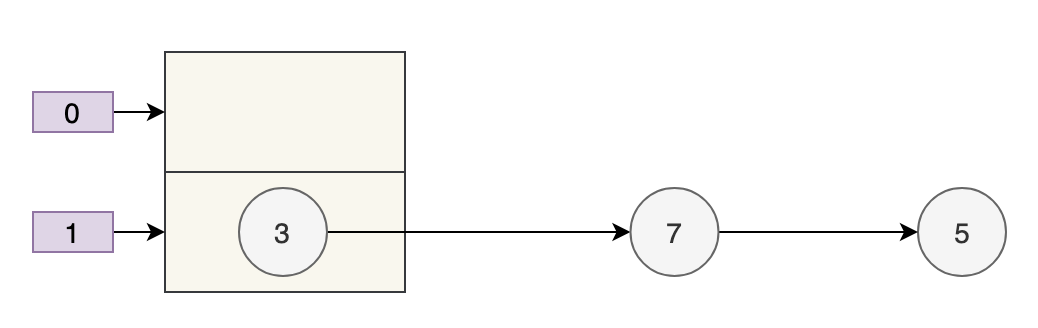
数组的容量为 2,key 为 3、7、5 的元素在 table[1] 上,需要通过拉链法来解决哈希冲突。
假设负载因子 loadFactor 为 1,也就是当元素的个数大于 table 的长度时进行扩容。
扩容后的数组容量为 4。
- key 3 取模(3%4)后是 3,放在 table[3] 上。
- key 7 取模(7%4)后是 3,放在 table[3] 上的链表头部。
- key 5 取模(5%4)后是 1,放在 table[1] 上。
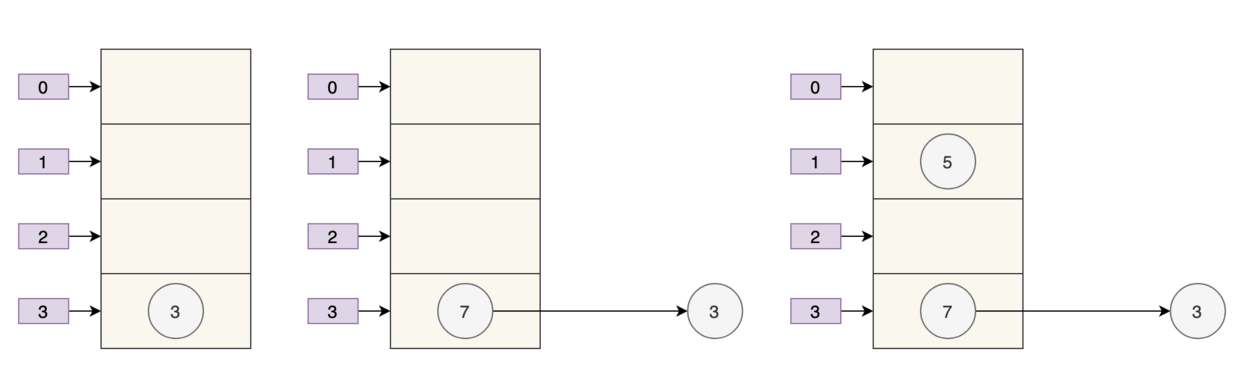
可以看到7跑到了3的前面,因为使用的是头插法:e.next= newTable[i];
JDK8则不是这样。主要是hash方法变了,由于数组的长度是2的N次幂,固定,新数组的大小是原来数组的两倍。那么新数组的长度-1,二进制表示跟原来的区别只有最左侧多了一位。
比如4->8,二进制表示的n-1就从 011 -> 111,那么此时计算数组下标,因为是用的&运算,所以新的下标只可能在原位置,或者是原位置+数组长度的位置。
加载因子为什么是0.75?
加载因子太小,则数组的利用率低,太大则哈希冲突的概率高,0.75是语言设计者找到的一个平衡点。
HashMap为什么线程不安全?
多线程下扩容会死循环(仅JDK1.7)
在JDK7中,HashMap在扩容时会调用transfer方法,这个方法在多线程下会形成环形链表,造成死循环。
// 同一位置上的新元素被放在链表的头部
e.next = newTable[i];
// 放在新的数组上
newTable[i] = e;上面写的是JDK1.7中transfer方法的场景。具体分析要看王二的HashMap详解
而JAVA8则没有这个问题,因为扩容机制变了,上面说过,新数组的位置只能是原位置或者原位置+数组长度。
多线程下put会导致元素丢失
多线程同时put,如果计算出的索引位置相同,会导致前一个key被后一个key覆盖掉。 问题发生在步骤 ② 这里:
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);put和get并发时会导致get到null
比如线程1put的时候,触发了扩容,其中有table=newTable这个语句,也就是转移引用到新的数组上,但是如果此时线程1还没有把旧的数组转移到新的数组上,此时切换到线程2中get,自然就get到null了。
LinkedHashMap详解
它能实现把元素按照插入顺序排列。如何做到?
LinkedHashMap重写了put()方法调用到的内部方法newNode();
//hashmap的
Node<K,V> newNode(int hash, K key, V value, Node<K,V> next) {
return new Node<>(hash, key, value, next);
}
//LinkedHashMap的
HashMap.Node<K,V> newNode(int hash, K key, V value, HashMap.Node<K,V> e) {
LinkedHashMap.Entry<K,V> p =
new LinkedHashMap.Entry<>(hash, key, value, e);
linkNodeLast(p);
return p;
}LinkedHashMap.Entry继承了HashMap.Node,并新增了两个属性before和after,用于记录前一个节点和后一个节点。
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}LinkedHashMap在插入节点时,会调用linkNodeLast()方法,把节点放到双向链表的尾部。然后更新before和after属性,以保证链表的顺序关系。
LinkedHashMap 在添加第一个元素的时候,会把 head 赋值为第一个元素,等到第二个元素添加进来的时候,会把第二个元素的 before 赋值为第一个元素,第一个元素的 afer 赋值为第二个元素。
这就保证了键值对是按照插入顺序排列的。
LinkedHashMap可以实现LRU
在初始化LinkedHashMap的时候,参数是可选的,有三个,如:new LinkedHashMap<>(16, .75f, true);当第三个参数为true的时候,就表明维护的是访问顺序,否则维护插入顺序。
TreeMap
有了HashMap和LinkedHashMap,为什么还需要TreeMap?
TreeMap中的元素是按key的自然顺序排列的!比如插入数字的key,那么输出时就是按照数字的升序输出。
内部在调用put()的时候,在插入完毕后会调用fixAfterInsertion()方法保证树的平衡状态。
它有lastKey(),firstKey()方法,可以获取最后一个key和第一个key。
TreeMap<Integer, String> treeMap = new TreeMap<>();
treeMap.put(1, "value1");
treeMap.put(2, "value2");
treeMap.put(3, "value3");
treeMap.put(4, "value4");
treeMap.put(5, "value5");
// headMap示例,获取小于3的键值对
Map<Integer, String> headMap = treeMap.headMap(3);
System.out.println(headMap); // 输出 {1=value1, 2=value2}
// tailMap示例,获取大于等于4的键值对
Map<Integer, String> tailMap = treeMap.tailMap(4);
System.out.println(tailMap); // 输出 {4=value4, 5=value5}
// subMap示例,获取大于等于2且小于4的键值对
Map<Integer, String> subMap = treeMap.subMap(2, 4);
System.out.println(subMap); // 输出 {2=value2, 3=value3}注意,TreeMap的话,查找效率是O(logN),因为底层是红黑树,所以查找效率是O(logN)。
ConcurrentHashMap
它是线程安全的哈希表实现,利用了锁分段的思想大大提高并发效率。
Java1.8开始有较大变化,抛弃segment,使用大量synchronized以及cas操作保证线程安全。
JDK1.7
在JDK1.7中,ConcurrentHashMap使用了分段锁机制,整个哈希表被分为多个段,每个段都独立锁定。
ConcurrentHashMap里包含着一个segment数组,一个segment里包含着一个HashEntry数组,每个HashEntry是一个链表结构的元素。当对 HashEntry 数组的数据进行修改时,必须首先获得它对应的 Segment 锁。
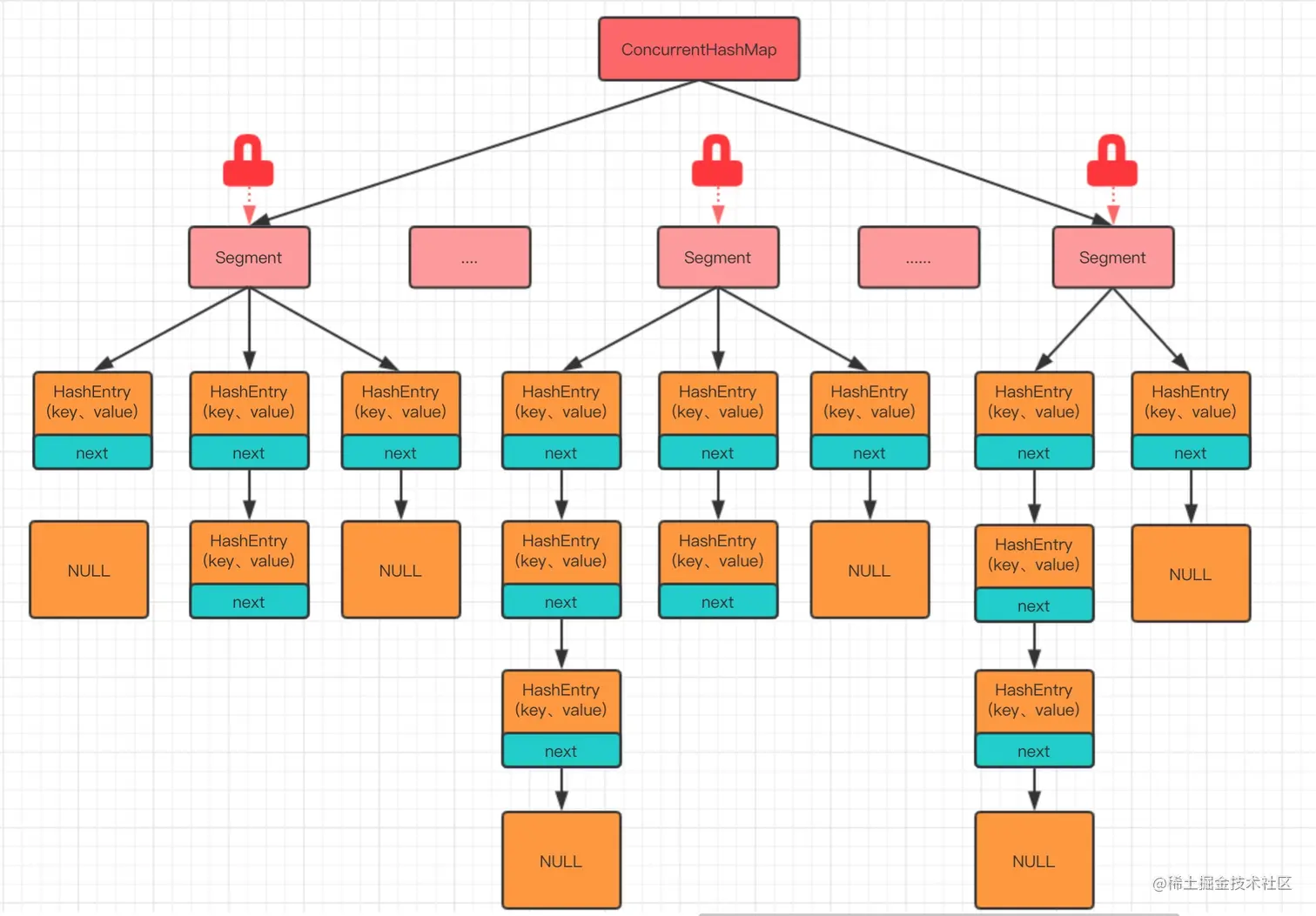
像这样的 Segment 对象,在 ConcurrentHashMap 集合中有多少个呢?有 2 的 N 次方个,共同保存在一个名为 segments 的数组当中。
可以说它是一个二级哈希表。不同segment的写入可以并发执行,同一segment的一写一读可以并发执行。同时写入就阻塞一个。
JDK1.8
在JDK1.8中,它做了两个优化:
- 跟HashMap一样,链表长度大于8就转成红黑树
- 以某个位置的头节点(链表的头节点或者红黑树的root节点)为锁,配合自旋+CAS避免不必要的锁开销,进一步提高并发性能。
在Java8中,取消了segment分段锁,采用CAS+synchronized保证并发安全性,整个容器只分为一个segment,即table数组。
JDK1.8 中的 ConcurrentHashMap 对节点 Node 类中的共享变量,和 JDK1.7 一样,使用 volatile 关键字,保证多线程操作时,变量的可见性!
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
volatile V val;
volatile Node<K,V> next;
Node(int hash, K key, V val, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.val = val;
this.next = next;
}
......
}initTable方法
如果多线程同时进入这个方法,为了保证能正确初始化,会先判断sizeCtl值,如果发现它<0,则说明有另一个线程在初始化,那么当前线程调用Thread.yield()方法让出CPU时间片。
正在进行初始化的线程会调用 U.compareAndSwapInt 方法将 sizeCtl 改为 -1,即正在初始化的状态。
put方法
怎么判断是不是特殊节点forwardingNode?是通过判断该节点的hash值是否为-1.
放入元素的时候,如果table[i]不为为null且不为forwardingNode,以及当前Node的hash值大于0(fh>=0)时,说明当前节点为链表的头节点,那么向ConcurrentHashMap插入新值就是往链表插入新值,通过synchronized保证安全。
总结:
- 每个放入的值,用spread方法计算hash值,确定下标
- 如果当前table还未初始化,进行初始化操作
- 如果当前table[i]为null,则利用CAS操作直接插入
- 如果当前table[i]不为null,先判断节点是不是为MOVED,如果是,则说明当前节点正在进行扩容。
- 如果是链表节点,就遍历寻找插入位置
- 如果节点类型是TreeBin,直接调用红黑树的插入方法插入新的节点
- 插入完成检查链表长度,大于8转红黑树
- 检查容量,大于临界值就扩容。
transfer方法
第一部分是构建一个 nextTable,它的容量是原来的两倍,这个操作是单线程完成的。
第二个部分是将原来 table 中的元素复制到 nextTable 中,主要是遍历复制的过程。 得到当前遍历的数组位置 i,然后利用 tabAt 方法获得 i 位置的元素:
小结
ConcurrentHashMap 是线程安全的,支持完全并发的读取,并且有很多线程可以同时执行写入。在早期版本(例如 JDK 1.7)中,ConcurrentHashMap 使用分段锁技术。整个哈希表被分成一些段(Segment),每个段独立加锁。这样,在不同段上的操作可以并发进行。从 JDK 1.8 开始,ConcurrentHashMap 的内部实现有了很大的变化。它放弃了分段锁技术,转而采用了更先进的并发控制策略,如 CAS 操作和红黑树等,进一步提高了并发性能。